
5ОсиXPath
Мы будем использовать следующий XML документ далее в примере.
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
Оси определяют наборы узлов, относительно текущего узла.
| Название оси | Результат |
|---|---|
| ancestor | Выбирает всех предков (родителей, прародителей и т.д.) текущего узла |
| ancestor-or-self | Выбирает всех предков (родителей, прародителей и т.д.) текущего узла и сам текущий узел |
| attribute | Выбирает все атрибуты текущего узла |
| child | Выбирает всех потомков текущего узла |
| descendant | Выбирает всех потомков (детей, внуков и т.д.) текущего узла |
| descendant-or-self | Выбирает всех потомков (детей, внуков и т.д.) текущего узла и сам текущий узел |
| following | Выбирает всё в документе после закрытия тэга текущего узла |
| following-sibling | Выбирает все узлы одного уровня после текущего узла |
| namespace | Выбирает все узлы в данном пространстве имён (namespace) текущего узла |
| parent | Выбирает родителя текущего узла |
| preceding | Выбирает все узлы, которые появляются перед текущим узлом в документе, за исключением предков, узлов атрибутов и узлы пространства имён |
| preceding-sibling | Выбирает всех братьев и сестёр до текущего узла |
| self | Выбирает текущий узел |
Обязательные элементы[править]
Корневым элементом документа является элемент . Этот элемент, в свою очередь, обязан содержать два (и только два) дочерних элемента:
- — метаданные (или «заголовок») документа в целом;
- — «тело».
Кроме того, данный элемент может содержать (незначимые) пробельные символы, комментарии, а также ряд атрибутов, три из которых (, , ) рассмотрены ниже.
Атрибуты lang и xml:langправить
В качестве пожелания, спецификация предлагает всегда указывать атрибут для элемента , определяя тем самым основной язык документа согласно BCP 47 (в простейшем случае — используя код языка ISO 639-1.)
Свойство языка наследуется дочерними элементами и может быть переопределено на любом уровне вложенности явным указанием атрибута .
В числе прочего, такое указание языка может способствовать использованию речевых синтезаторов и программ автоматизированного перевода, корректной работе Web-поиска, а равно и правильному выбору шрифтовых вариантов некоторых букв (cf.: серб. буква и рус. буква.)
Спецификация XML предусматривает для указания языка атрибут . Использование этого атрибута может быть полезно из соображений совместимости с инструментами обработки XML, не реализующими особо поддержку HTML5. Если при этом также используется и атрибут , его значение обязано совпадать с таковым для .
С целью обеспечения некоторой «совместимости» между представлениями HTML и XHTML, HTML5 допускает использование атрибута также и в HTML-представлении. В этом случае, данный атрибут обязан дублировать атрибут элемента; использование отдельно от , или с отличным значением, не допускается.
Атрибут dirправить
Наряду с , для корректного воспроизведения многоязычных текстов также важен атрибут , определяющий направление письма для содержания элемента, и допускающий три возможных значения:
- — направление письма для данного элемента — слева-направо (от англ. left-to-right);
- — справа-налево (от англ. right-to-left); применимо для языков на основе арабского письма, иврита, etc.;
- — направление письма для данного элемента следует определить автоматически, независимо от направления письма для родительского элемента; (по-умолчанию, направление письма наследуется элементами-потомками.)
Как и в случае , направление письма наследуется дочерними элементами и может быть переопределено на любом уровне вложенности явным указанием атрибута .
Спецификация HTML5 предлагает использовать вариант только в исключительных случаях, когда направление письма содержащегося в элементе текста действительно не может быть установлено сколь угодно достоверно.
Атрибут xmlnsправить
При использовании представления на основе XML (XHTML), элементы HTML должны быть отнесены к соответствующему пространству имен, чего обычно можно достичь используя атрибут в форме для корневого элемента, как показано
В представлении HTML данный атрибут не используется и допускается спецификацией в том и только том случае, когда имеет указанное значение.
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор
символов.
Самыми распространенными кириллическими кодировками являются и . Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку .
В XML файле кодировка объявляется в декларации:
<?xml version="1.0" encoding="windows-1251"?>
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Коды распространенных языков
| Язык | Код |
|---|---|
| Абхазский | ab |
| Азербайджанский | az |
| Аймарский | ay |
| Албанский | sq |
| Английский | en |
| Американский английский | en-us |
| Арабский | ar |
| Армянский | hy |
| Ассамский | as |
| Африкаанс | af |
| Башкирский | ba |
| Белорусский | be |
| Бенгальский | bn |
| Болгарский | bg |
| Бретонский | br |
| Валлийский | cy |
| Венгерский | hu |
| Вьетнамский | vi |
| Галисийский | gl |
| Голландский | nl |
| Греческий | el |
| Грузинский | ka |
| Гуарани | gn |
| Датский | da |
| Зулу | zu |
| Иврит | iw |
| Идиш | ji |
| Индонезийский | in |
| Интерлингва (искусственный язык) | ia |
| Ирландский | ga |
| Исландский | is |
| Испанский | es |
| Итальянский | it |
| Казахский | kk |
| Камбоджийский | km |
| Каталанский | ca |
| Кашмирский | ks |
| Кечуа | qu |
| Киргизский | ky |
| Китайский | zh |
| Корейский | ko |
| Корсиканский | co |
| Курдский | ku |
| Лаосский | lo |
| Латвийский, латышский | lv |
| Латынь | la |
| Литовский | lt |
| Малагасийский | mg |
| Малайский | ms |
| Мальтийский | mt |
| Маори | mi |
| Македонский | mk |
| Молдавский | mo |
| Монгольский | mn |
| Науру | na |
| Немецкий | de |
| Непальский | ne |
| Норвежский | no |
| Пенджаби | pa |
| Персидский | fa |
| Польский | pl |
| Португальский | pt |
| Пуштунский | ps |
| Ретороманский | rm |
| Румынский | ro |
| Русский | ru |
| Самоанский | sm |
| Санскрит | sa |
| Сербский | sr |
| Словацкий | sk |
| Словенский | sl |
| Сомали | so |
| Суахили | sw |
| Суданский | su |
| Тагальский | tl |
| Таджикский | tg |
| Тайский | th |
| Тамильский | ta |
| Татарский | tt |
| Тибетский | bo |
| Тонга | to |
| Турецкий | tr |
| Туркменский | tk |
| Узбекский | uz |
| Украинский | uk |
| Урду | ur |
| Фиджи | fj |
| Финский | fi |
| Французский | fr |
| Фризский | fy |
| Хауса | ha |
| Хинди | hi |
| Хорватский | hr |
| Чешский | cs |
| Шведский | sv |
| Эсперанто (искусственный язык) | eo |
| Эстонский | et |
| Яванский | jw |
| Японский | ja |
Localization process
If you want to localize an XML file, it means that you most like have text data in your XML file. Take a look at the following simple XML file.
<?xml version="1.0" encoding="utf-8"?> <simple> <product>Skim milk</product> <price>1.15</price> <onsale>0</onsale> </simple>
You can find the file from <data-dir>\Samples\XML\Simple\Simple.xml. The file has a product element that contains the English text: «Skim milk.» This needs to be translated. If we translate the above file into German, we will get:
<?xml version="1.0" encoding="utf-8"?> <simple> <product>Magermilch</product> <price>1.15</price> <onsale>0</onsale> </simple>
The structure of the German XML file is identical to the structure of the original English XML file; only the text in the product element has been translated into German.
When you add an XML file into the Soluling project, you need to select what elements are localized. This is done on the XML items sheet of Project Wizard or Source dialog.

You have three choices to select what to localize:
Localize all items of selected types
If you leave the Localize all items of selected types checked, Soluling extracts everything that contains the text. From the above XML file the product element would be translated, and the price and onsale elements would be ignored. The default feature is to translate all string data, but you can add other data types too.
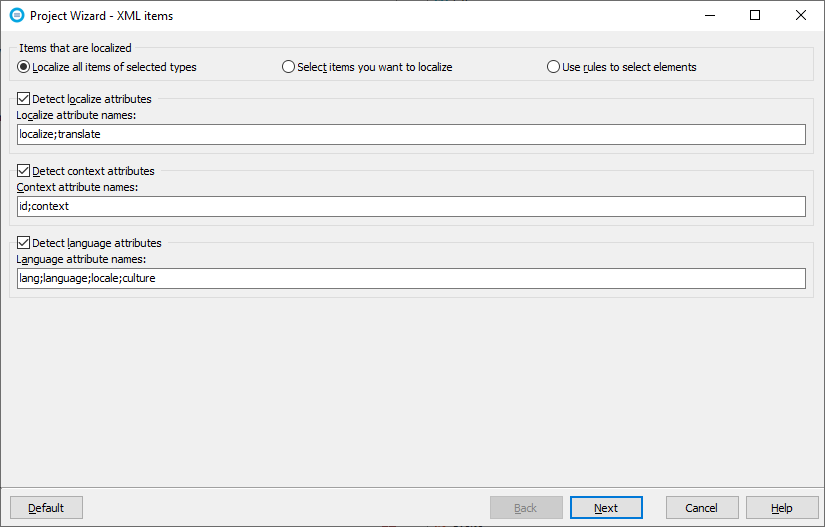
When you click Next, the Project Wizard shows the data types sheet that lets you select the data types that are localized. By default, the string type is checked, and all others unchecked. If you want to localize the numbers too, check either Float or Integer or both. You can also configure if and how the , and attributes are used.
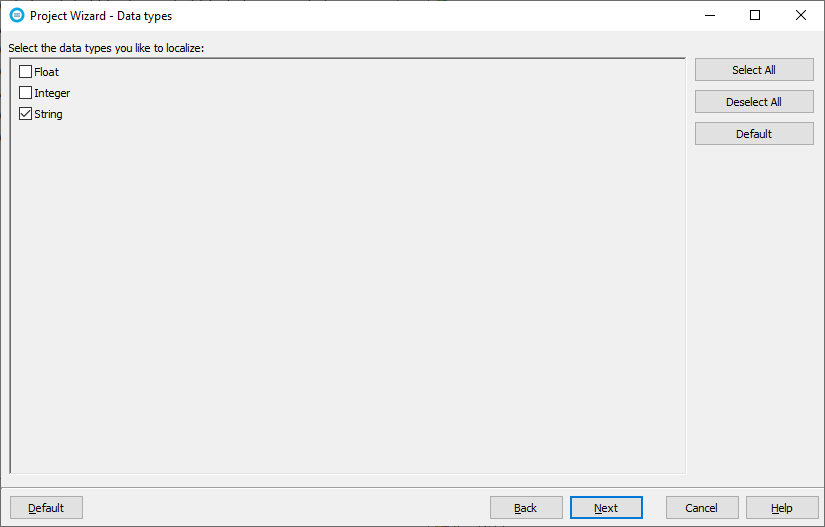
Even all XML data is text data, the actual value can and in most cases, is something else but text. It can be a number, color value, boolean value, or even an image encoded into base64 string. Soluling automatically detects the format. Of course, this detection is not always 100% accurate. For example, the string «0» can either mean number 0, the boolean value false, or the string «0». Also, string «true» can either be boolean value true or the string «true.» If the default detection of Soluling does not get the type correctly or you need a more sophisticated way to choose what elements are translated and how the element data is interpreted to use the Select items you want to localize.
Select items you want to localize
If you check Select items you want to localize radio button Soluling shows selection tree that contains the structure of the XML file where you can check those elements that you want to localize. To check or uncheck an element, double click it. To specify the data type of the element right-click and set the format.
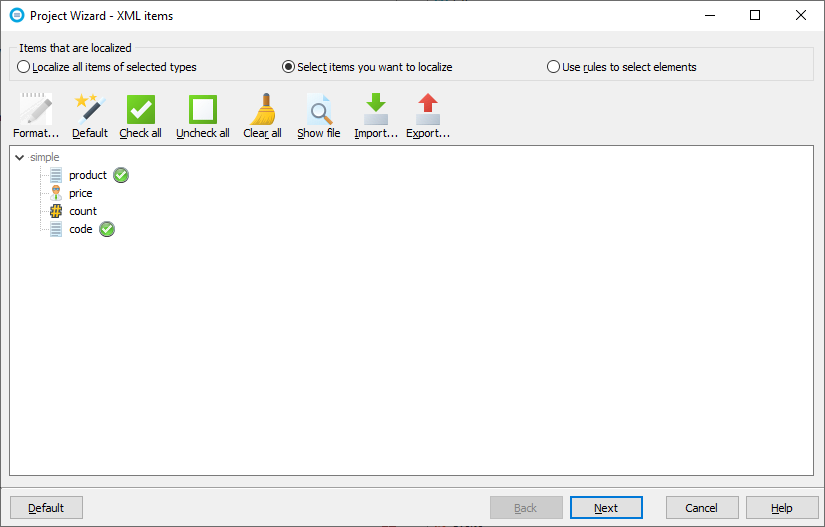
Data types sheet is not visible when you have turned on the item selections. This is because the selection also specifies the data type of each element that is selected. Data types sheet is not needed.
Use rules rules to select elements
If you seletc Use rules to select elements radio button Soluling shows the element select rule editor. Use the editor you add one ore more XPath based element rules. Each rule selects all the elements that match the XPath expression given in the rule.
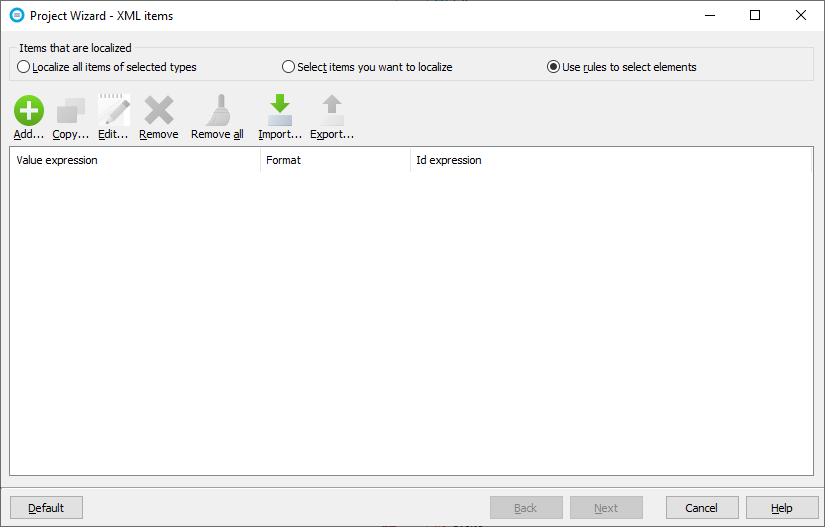
Click the Add button to show the Select Rule dialog. Enter product in the Value expression field and click OK.
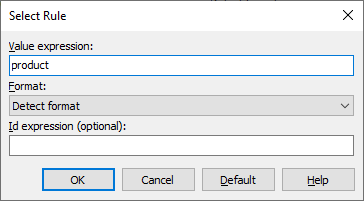
Click OK to add the rule. Now you have told Soluling to localize all elements in your XML file. The Id expression field is optional. If the XML element contains an attribute or sibling element that specifies the id, enter the XPath to that element. It tells Soluling to use the value of the attribute or element as a context value for the value.
Элемент title[править]
Обязательный элемент должен, в свою очередь, содержать элемент , содержащий заглавие документа. Этот элемент может присутствовать в документе лишь в единственном экземпляре, и только как дочерний для элемента . Содержанием данного элемента может быть только текст, — вложенные элементы не допускаются.
В тех случаях, когда заглавие может быть определено из контекста передачи документа (как, например, при передаче документа электронной почтой), спецификация позволяет не указывать данный элемент. На практике, однако, существующие системы проверки действительности документов HTMLвсегда требуют наличия данного элемента.
The value of reuse
A more interesting dicussion is the value of reuse, which varies greatly from both where it’s applied and used.
The XML Schema itself reuses the type several times as an syntactic component, since it very generic only constraining to Name something and with an attribute to described the language. The URL variant is only used once and in general since an empty value is allowed I would have liked the attribute to be optional instead of required.
The value of reusing could be argued as minimal, since it would be easy to redefine without to much struggle, and the level of generic support for this attribut is in my opinion limited and tied to the domain/application use.
Update! Since making this post I’ve had some experience with it in XMLBeans which actually has some built in checks that surpass the definition in the xml.xsd:
92 <xs:attribute name="lang"> 93 <xs:annotation> 94 <xs:documentation>Attempting to install the relevant ISO 2- and 3-letter 95 codes as the enumerated possible values is probably never 96 going to be a realistic possibility. See 97 RFC 3066 at http://www.ietf.org/rfc/rfc3066.txt and the IANA registry 98 at http://www.iana.org/assignments/lang-tag-apps.htm for 99 further information. 100 101 The union allows for the 'un-declaration' of xml:lang with 102 the empty string.</xs:documentation> 103 </xs:annotation> 104 <xs:simpleType> 105 <xs:union memberTypes="xs:language"> 106 <xs:simpleType> 107 <xs:restriction base="xs:string"> 108 <xs:enumeration value=""/> 109 </xs:restriction> 110 </xs:simpleType> 111 </xs:union> 112 </xs:simpleType> 113 </xs:attribute>
For one it checks that the overall syntax is correct, ex. It’ll call it an error if I use instead of and doesn’t allow for it to be empty like the xml.xsd states (which is fine by me since I personally dislikes empty elements and attributes in data-centric scenarios).
Специфические xsd:documentation и xsd:appinfo
| Вид аннотации | Пояснения |
| Краткое наименование поля, может использоваться для автоматической генерации интерфейсов и печатных форм. | |
| Заполняется, если для данного поля есть соответствие в приказе ФСФР. | |
| Расширенное описание поля. | |
| Условия заполнения данного поля, если таковые имеются. | |
|
mre – mandatory reporting element. Поля, обязательные к заполнению. Элементы схемы, отмеченные таким атрибутом обязательно должны быть заполнены в сообщении, присылаемом на регистрацию в репозитарий. Данный флаг может дополнительно иметь значение, например, . Значение задаёт минимально возможное вхождение элемента в сообщение. С точки зрения правил xsd этот атрибут эквивалентен атрибуту , однако он не может быть свалидирован стандартными средствами. При наличии у элемента такого флага атрибут не учитывается. |
|
| mfr – mandatory field reconciliation Поля обязательной сверки – поля, обязательные и необязательные к заполнению, которые должны совпадать в обоих встречных сообщениях для успешного прохождения регистрации. Заполненные поля в сообщениях одной стороны и незаполненные поля во встречных сообщениях второй стороны признаются несовпадающими. Незаполненные (необязательные к заполнению) поля во встречных сообщениях обеих сторон признаются совпадающими. | |
| afr – additional field reconciliationПоля дополнительной сверки – поля, необязательные к заполнению и для прохождения регистрации. В случае заполнения и полного совпадения этих полей во встречных сообщениях обеих сторон, сведения из этих полей вносятся в реестр договоров. В случае незаполнения этих полей или несовпадения их во встречных сообщениях сторон, сведения из этих полей не вносятся в реестр договоров. Однако факт несовпадения этих полей не влечет за собой отказ в регистрации сообщений, которые будут зарегистрированы в реестре без данных полей. | |
| sfr – special field reconciliation Поля специальной сверки – поля, обязательные для прохождения регистрации, расхождение в заполнении которых во встречных сообщениях двух сторон, если поля заполнены обеими сторонами, приводит к отказу в регистрации сообщений. В случае, если эти поля заполнены только одной стороной, поля считаются сверенными, а значения этих полей, заполненные одной стороной, вносятся в реестр как значения, принятые для данных полей. | |
| ofr – optional field reconciliation Поля специальной дополнительной сверки – поля, необязательные для прохождения регистрации, расхождение в заполнении которых во встречных сообщениях двух сторон, если поля заполнены обеими сторонами, не приводит к отказу в регистрации сообщений – сообщения регистрируются, но сведения из этих полей не вносятся в реестр договоров. В случае, если эти поля заполнены только одной стороной, поля считаются сверенными, а значения этих полей, заполненные одной стороной, вносятся в реестр как значения, принятые для данных полей. | |
| nfr – no field reconciliation Несверяемые поля – поля сообщений, которые не участвуют в процессе сверки. Эти поля служат для передачи технической информации о сообщении (отправитель, номер сообщения и пр.). Значения этих полей из сообщений обеих сторон не вносятся в реестр. | |
| ncf – non-completed field Незаполняемые поля – поля, предусмотренные в формате сообщений, не используемые в целях обмена сообщениями с репозитарием. Сведения, указанные в таких полях, не заполняются сторонами, а в случае заполнения не подлежат сверке и внесению в реестр. | |
| umf – unique matching field Поля, определяющие уникальность анкеты – поля обязательной либо дополнительной сверки, обеспечивающие уникальность регистрируемых анкет генеральных соглашений, договоров и иных отчетов и поиск встречных анкет при квитовке сообщений. | |
| Цифровое поле, к которому применяется следующее условие: точность до 7 знаков после десятичной точки; например, 30.1234567; значение 30.45 указывается как 30.4500000 |
Localize attribute
Sometimes you need finer control over what elements are localized than the selection tree can offer. For example, you might be several elements with the same name, but there is one element that you don’t what to localize. For example, the following XML file contains one value element that should be localized and another that should not be localized.
<?xml version="1.0" encoding="UTF-8"?> <sample> <value>Translate this</value> <value>Do not translate this</value> </sample>
How can you solve this? The answer is to use a localize attribute. It is a boolean attribute that either sets a positive or negative localize flag. A positive attribute contains a value (e.g. «true», «yes» or «1»). A negative attribute, contains a negative value (e.g. «false», «no» or «0»). If you add a negative localize attribute Soluling will not localize that value element even if you check it in the selection tree.
<?xml version="1.0" encoding="UTF-8"?> <sample> <value>Translate this</value> <value localize="false">Do not translate this</value> </sample>
Here is a positive localize attribute.
<?xml version="1.0" encoding="UTF-8"?> <sample> <value localize="true">Translate this</value> <value>Do not translate this</value> </sample>
Of course, you can add both negative and positive attributes in the same XML file.
<?xml version="1.0" encoding="UTF-8"?> <sample> <value localize="true">Translate this</value> <value localize="false">Do not translate this</value> </sample>
Use the Options sheet to specify what values make positive and negative localize attributes. The sheet contains Localize attribute group box that is used to specify positive and negative localize attribute values.

The localize attribute is stronger than selection. Even if you have not checked an element, but it contains a positive localize attribute, the element is localized. If you check to Localize only those elements that have positive localize attribute checkbox, then Soluling localizes only those elements that have a positive localize attribute. So even element has been checked in the selection but if it does not have a positive localize attribute it is not localized. By default, Soluling will handle «localize» and «translate» attributes as localize attributes. You can turn any attribute into a localize attribute by using the selection tree.
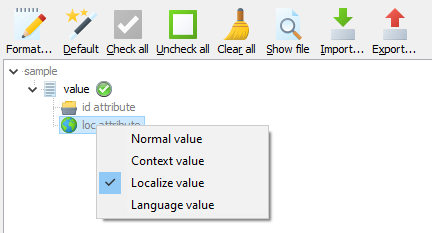
Soluling did not detect loc as localize attribute, but the user has manually set the loc attribute as the localize attribute.
How do I use the lang() function in XPath?
XPath offers a dedicated function to identify the language of a given
node: . The function returns true if the node has a
attribute set that matches the language code you specified.
The matching is based on sub-string comparison of the start of the
value. For example: will match ,
, and ,
but will not match . The same
way will match ,
but not .
The matching is not case-sensitive. For example:
will match all case combinations, such as ,
, ,
and so forth.
Example of usage: The following XML document contains
elements in different languages.
<?xml version="1.0" encoding="iso-8859-1" ?> <?xml-stylesheet type="text/xsl" href="Languages.xsl" ?> <MyData> <Msg id="100"> <Text xml:lang="en">Message 100 in English.</Text> </Msg> <Msg id="200"> <Text xml:lang="en-us">Message 200 in American English.</Text> <Text xml:lang="fr-CA">Message 200 en Quйbecquois.</Text> </Msg> <Msg id="300"> <Text xml:lang="fr">Message 300 en franзais.</Text> </Msg> <Msg id="400"> <Text xml:lang="EN-GB">Message 400 in British English.</Text> </Msg> </MyData>
The following XSL template will output only the content of the
elements that match the value set for the parameter
(here: ).
<?xml version="1.0" ?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:param name="OutLang">en</xsl:param> <xsl:template match="Text"> <xsl:if test="lang($OutLang)"> <p><xsl:value-of select="."/> (<xsl:value-of select="@xml:lang"/>)</p> </xsl:if> </xsl:template> </xsl:stylesheet>
Display the document (you
need a browser that support XML and XSL).
1Что такое XPath
|
Выражения XPath
XPath использует выражения пути для выбора отдельных узлов или набора узлов в документе XML. Эти выражения очень похожи на выражения, которые вы видите, когда работаете с традиционной файловой системой компьютера.
Стандартные функции XPath
XPath включает в себя более 100 встроенных функций. Есть функции для строковых и числовых значений, даты и времени, сравнения узлов и манипулирования QName, управления последовательностями, булевых значений, и многое другое.
XPath используется в XSLT
XPath является одним из основных элементов в стандарте XSLT. Без знания XPath вы не будете иметь возможность создавать XSLT-документы.
XPath является рекомендацией консорциума W3C
XPath стал рекомендацией W3C 16 ноября 1999 года. XPath был разработан для использования в XSLT, XPointer и другом программном обеспечении для разбора (парсинга) документов XML.
Glossary
Abstract
(Applies to complex type definitions and element declarations). An abstract element or complex type cannot used to validate an element instance. If there is a reference to an abstract element, only element declarations that can substitute the abstract element can be used to validate the instance. For references to abstract type definitions, only derived types can be used.
All Model Group
Child elements can be provided in any order in instances. See: .
Choice Model Group
Only one from the list of child elements and model groups can be provided in instances. See: .
Collapse Whitespace Policy
Replace tab, line feed, and carriage return characters with space character (Unicode character 32). Then, collapse contiguous sequences of space characters into single space character, and remove leading and trailing space characters.
Disallowed Substitutions
(Applies to element declarations). If substitution is specified, then members cannot be used in place of the given element declaration to validate element instances. If derivation methods, e.g. extension, restriction, are specified, then the given element declaration will not validate element instances that have types derived from the element declaration’s type using the specified derivation methods. Normally, element instances can override their declaration’s type by specifying an attribute.
Key Constraint
Like , but additionally requires that the specified value(s) must be provided. See: .
Key Reference Constraint
Ensures that the specified value(s) must match value(s) from a or . See: .
Model Group
Groups together element content, specifying the order in which the element content can occur and the number of times the group of element content may be repeated. See: .
Nillable
(Applies to element declarations). If an element declaration is nillable, instances can use the attribute. The attribute is the boolean attribute, nil, from the http://www.w3.org/2001/XMLSchema-instance namespace. If an element instance has an attribute set to true, it can be left empty, even though its element declaration may have required content.
Notation
A notation is used to identify the format of a piece of data. Values of elements and attributes that are of type, NOTATION, must come from the names of declared notations. See: .
Preserve Whitespace Policy
Preserve whitespaces exactly as they appear in instances.
Prohibited Derivations
(Applies to type definitions). Derivation methods that cannot be used to create sub-types from a given type definition.
Prohibited Substitutions
(Applies to complex type definitions). Prevents sub-types that have been derived using the specified derivation methods from validating element instances in place of the given type definition.
Replace Whitespace Policy
Replace tab, line feed, and carriage return characters with space character (Unicode character 32).
Sequence Model Group
Child elements and model groups must be provided in the specified order in instances. See: .
Substitution Group
Elements that are members of a substitution group can be used wherever the head element of the substitution group is referenced.
Substitution Group Exclusions
(Applies to element declarations). Prohibits element declarations from nominating themselves as being able to substitute a given element declaration, if they have types that are derived from the original element’s type using the specified derivation methods.
Target Namespace
The target namespace identifies the namespace that components in this schema belongs to. If no target namespace is provided, then the schema components do not belong to any namespace.
Uniqueness Constraint
Ensures uniqueness of an element/attribute value, or a combination of values, within a specified scope. See: .
Global Declarations
Attribute: base
| Name | base |
|---|---|
| Used by (from the same schema document) | Attribute Group |
| Type |
:anyURI |
| Documentation | See http://www.w3.org/TR/xmlbase/ for information about this attribute. |
XML Instance Representation
:base=»
:anyURI»
Diagram

Schema Component Representation
<xs:attribute
name=»base» type=»
:anyURI
«/>
Attribute: id
| Name | id |
|---|---|
| Used by (from the same schema document) | Attribute Group |
| Type |
:ID |
| Documentation | See http://www.w3.org/TR/xml-id/ for information about this attribute. |
XML Instance Representation
:id=»
:ID»
Diagram

Schema Component Representation
<xs:attribute
name=»id» type=»
:ID
«/>
Attribute: lang
| Name | lang |
|---|---|
| Used by (from the same schema document) | Attribute Group |
| Type | Locally-defined simple type |
| Documentation |
Attempting to install the relevant ISO 2- and 3-letter The union allows for the ‘un-declaration’ of xml:lang with |
XML Instance Representation
:lang=»union of: ]»
Diagram
Schema Component Representation
<xs:attribute
name=»lang»><xs:simpleType><xs:union
memberTypes=»
:language»><xs:simpleType><xs:restriction
base=»
:string
«><xs:enumeration
value=»»/></xs:restriction></xs:simpleType></xs:union></xs:simpleType></xs:attribute>
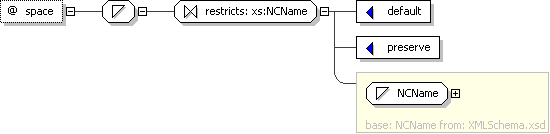
Attribute: space
| Name | space |
|---|---|
| Used by (from the same schema document) | Attribute Group |
| Type | Locally-defined simple type |
XML Instance Representation
:space=»
:NCName (value comes from list: {‘default’|’preserve’})»
Diagram

Schema Component Representation
<xs:attribute
name=»space»><xs:simpleType><xs:restriction
base=»
:NCName
«><xs:enumeration
value=»default»/>
<xs:enumeration
value=»preserve»/></xs:restriction></xs:simpleType></xs:attribute>
What about multilingual documents?
You can have different languages within the same document. If you have
such documents, make sure to use the attribute to
identify the language of each part of the content.
However, from a localization viewpoint, such documents are not
currently easy to localize and their use is not recommended if you do not
have a clear and efficient process in place to handle their translation.
See an example of XML document in 15 languages:
With
a simple style sheet, and
without
a style sheet. (You need a browser with XML and CSS support to display
both documents correctly. Note also that some characters may be
represented as blocks if you do not have a font to display them).
Ответ
Когда использовать xml:lang
Контент, непосредственно связанный с XML документом (или содержится непосредственно в документе или рассматривается как часть документа когда он обрабатывается или предоставляется) должен использовать атрибут xml:lang для указания языка контента. xml:lang имеет резервироваться для авторов контента для непосредственного обозначения любого естественного речевого контента, что они могут иметь.
xml:lang определяется в XML 1.0 как общий атрибут, который может использоваться для определения языка любого контента element (елемента). Сюда включается как текст, который можно прочитать, так и другой контент (такой как встроенные объекты, такие как изображения и звуковые файлы), содержащийся в element (элементе) в котором он появился. Значение xml:lang применяется к любым sub-elements, содержащихся в element (элементе). Это также применяется к значениям атрибута, которые связаны с element и sub-elements (Хотя использование естественного языка в атрибутах это не лучшая идея). Значение атрибута xml:lang — это language тэг, который определяется в BCP 47.
Например, вот xml:lang в element (элементе) t :
Этот пример показывает, как xml:lang применяется к атрибуту:
Когда следует использовать свой собственный element (элемент) или attribute (атрибут)
Когда значение языка — на самом деле является атрибутом или meta данными для некоторого внешнего контента, тогда xml:lang не следует использовать. В этих случаях вы хотите сохранить информацию о языке, но язык непосредственно не относится к содержанию XML документа (или содержит такой контент, как изображения, которые обрабатываются как часть документа). В этом случае вы должны определить элемент или атрибут используя другое название и не следует использовать атрибут xml:lang . Для выбора значения элемента или атрибута следует использовать BCP 47, так же, как для xml:lang .
Некоторые примеры этого могут включать в себя:
- element (элемент) в XML документе описывает вашу коллекцию DVD для того, чтобы определить, какие языки доступны на звуковой дорожке
- element (элемент) в клиентской базе данных с полем для языка которой пользователь предпочитает
- attribute (атрибут) link element (элемента ссылки) (такой как a в XHTML), что указывает на написанную на другом языке версию этого документа
Вам следует создать ваш собственный element (элемент) (или attribute (атрибут)) тогда, когда есть необходимость передать значение языка (как часть структуры данных или как meta данные для внешнего документа), а не чтобы указать язык конкретной части контента. Не используйте xml:lang для описания значений внешне языка — это позволит избежать создания проблем для авторов контента, которым необходимо отмечать контент для обработки текстов.
Например, документ XML может выглядеть так:
В этом примере атрибут xml:lang передает информацию о естественном языке текста, который появляется в этом документе. Элемент dialogue (диалог) и атрибут language (язык) элемента subtitles (подзаголовки) определены в схеме XML документа и передают значение естественного языка, который с ними связан. Например, он передает информацию, с subtitles (подзаголовки), что написанные на Track (запись) #1 или показанные на Традиционном Китайском языке ( zh-Hant ).
2Терминология XPath
Узлы
В XPath существует семь видов узлов: элемент, атрибут, текст, пространство имён, инструкции обработки, комментарии и узлы документа. XML-документы обрабатываются в виде деревьев узлов. Верхний элемент дерева называется корневым элементом. Посмотрите на следующий документ XML:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J. K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
Пример узлов в документе XML выше:
<bookstore> (корневой элемент) <author>J. K. Rowling</author> (узел) lang="en" (атрибут)
Атомарные значения являются узлами, не имеющие детей или родителей. Пример атомарных значений:
J. K. Rowling "en"
xml:space
Section 2.10 of the XML Recommendation defines a new attribute that allows elements to declare to an application whether their white space is ‘significant’. This will probably receive extensive use in combination with XSL or perhaps the CSS white-space property to display documents correctly. Validating processors already must pass all non-markup characters to the application, and inform them of the element in which they appeared. This attribute acts as a flag, telling the application whether or not it should pay attention to the white space characters.
Note: It remains up to the application whether it actually does anything with the white space characters. While I expect that browsers and some other XML display applications will take heed of xml:space, many other applications will find it irrelevant.
The xml:space attribute is declared as follows: (Note that this attribute still must be declared.)
The xml:space behavior is inherited from parent elements; if an element containing an xml:space value contains other elements, they too will handle white space as specified by the parent element. This can be overridden by a new xml:space atrribute in the child elements.
Because a default can be set in the DTD, it’s simple to create documents that pay attention to white space by default; just set the default value of the xml:space for the root element to ‘preserve’. For more consistent results (remember, parts of your XML document may be returned through XML-Link), assign this as the default value to all of your element types.
Общие атрибуты
Ниже представлена таблица некоторых других атрибутов, которые можно легко использовать со многими html-тегами.
| Атрибут | Опция | Функция |
| align | right, left, center | Горизонтальное выравнивание тегов. |
| valign | top, middle, bottom | Вертикально выравнивает тегов внутри html-элемента. |
| bgcolor | числовые, шестнадцатеричные, RGB значения | Помещает фоновый цвет за элемент. |
| background | URL | Помещает фоновое изображение за элемент. |
| id | определяется пользователем | Именование элемента для использования с каскадными таблицами стилей. |
| class | определяется пользователем | Классифицирует элемент для использования с каскадными таблицами стилей. |
Мы ещё увидим соответствующие примеры атрибутов при изучении других html-тегов (полный список html-тегов и связанных атрибутов).
What is the xml:lang attribute?
The attribute is a reserved attribute of XML to
specify the language of a given content. Its purpose is to allow all
different XML document types to use the same attribute for language
identification.
The attribute applies to all attributes
(regardless their order) and content of the element where it appears and
all children of that element, except when overwritten. For example:
<?xml version="1.0" encoding="utf-8" ?> <doc xml:lang="en"> <list title="Titre en franзais" xml:lang="fr"> <p>Texte en franзais.</p> <p xml:lang="fr-ca">Texte en quйbйcquois.</p> <p xml:lang="en">Second text in English.</p> </list> <p>Text in English.</p> </doc>
Always use the attribute to specify the language of a content:
its use is assumed in many other XML-related technologies. For example, .