
Введение
Сегодня в век информационных технологий, когда информационные потоки подходят к определённому пределу плотности трафика каналов передачи, вместе с задачами информационной обработки, стоят и самые важные задачи ее упорядочивания, сохранения и обеспечения к ней оперативного доступа.
Именно поэтому знание принципов формирования и работы, а также оптимальное создание и работа с разными структурами хранения информационных данных, тот есть, с файлами, базами данных, файловыми системами, считается одним из наиболее важных аспектов.
Компьютер является электронной системой, работающей с информацией в виде сигналов. Компьютер способен работать лишь с такой информацией, которую возможно преобразовать в сигналы. Компьютер способен отлично работать с числовой информацией. Любое число в компьютере представлено своим двоичным кодом, то есть, закодировано при помощи только двух символов единица и нуль, которые достаточно просто могут быть представлены в виде сигналов. Весь информационный набор, который использует компьютер, может быть закодирован совокупностью чисел. Вне зависимости от типа информации (графика, текст или звук), что бы её смог обработать центральный процессор она должна быть отображена в виде набора чисел.
Что такое бит и что такое байт
Один двоичный знак — 0 или 1 – называется бит (англ. bit – сокращение от английских слов binary digit, что означает двоичная цифра). Бит представляет наименьшую единицу информации. Однако компьютер имеет дело не с отдельными битами, а с байтами.
Байт (англ. byte) – число из восьми бит (различные комбинации из восьми нулей и единиц). Байт является единицей измерения информации.
Последовательностью битов можно закодировать текст, изображение, звук или какую-либо другую информацию. Такой метод представления информации называется двоичным кодированием (binary encoding).
О представлении информации в компьютере
Чтобы перевести в цифровую форму музыкальный звук, можно применить такое устройство, как аналого-цифровой преобразователь. Он из входного звукового (аналогового) сигнала на выходе дает последовательность байтов (цифровой сигнал).
Обратный перевод можно сделать с помощью другого устройства – цифро-аналогового преобразователя, и таким образом воспроизвести записанную музыку.
На самом деле роль преобразователей (аналого-цифрового и цифро-аналогового) выполняют специальные компьютерные программы. Поэтому при использовании компьютера надобности в таких устройствах нет.
Похожим образом обрабатывается и текстовая информация. При вводе в компьютер каждая буква и каждый знак (цифры, знаки препинания, пробел, математические знаки и др.) кодируется, так чтобы один символ занимал 1 байт памяти (восемь бит, сочетание 8-и единиц и нулей). А при выводе на экран монитора или на принтер по этим байтам заново воспроизводятся соответствующие изображения символов текста, понятные человеку.
Сохранить можно не только текстовую и звуковую информацию. В виде кодов хранятся и изображения. Если посмотреть на рисунок с помощью увеличительного стекла, то видно, что он состоит из точек одинаковой величины и разного цвета – это так называемый растр.
Координаты каждой точки можно запомнить в виде числа, цвет точки – это еще одно число для последующего кодирования. Эти числа могут храниться в памяти компьютера и передаваться на любые расстояния. По ним компьютерные программы способны воспроизвести рисунок на экране монитора или напечатать его на принтере. Изображение можно увеличить или уменьшить, сделать темнее или светлее. Его можно повернуть, наклонить, растянуть.
Мы считаем, что на компьютере обрабатывается изображение. Но на самом деле компьютерные программы изменяют числа, которыми отдельные точки изображения представлены (точнее, сохранены) в памяти компьютера.
Таким образом, компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть предварительно преобразована в числовую форму при помощи соответствующих компьютерных программ.
Язык, понятный современной технике
Конечно, алгоритм считывания двоичного кода процессорными устройствами намного сложнее. Но зато его помощью можно записать все что угодно:
- Текстовую информацию с параметрами форматирования;
- Числа и любые операции с ними;
- Графические и видео изображения;
- Звуки, в том числе и выходящие и за предел нашей слышимости;
Помимо этого, благодаря простоте «изложения» возможны различные способы записи бинарной информации:
Дырочки на перфоленте и перфокарте, соответствующие «1», были одновременно и одним из языков программирования;
Чередование ровной поверхности и выжженных впадин используется в CD и DVD дисках;
- Состоянием отдельных элементов группы транзисторов в USB накопителях;
- Изменением магнитного поля на HDD дисках;
Дополняет преимущества двоичного кодирования практически неограниченные возможности по передаче информации на любые расстояния. Именно такой способ связи используется с космическими кораблями и искусственными спутниками.
Так что, сегодня двоичная система счисления является языком, понятным большинству используемых нами электронных устройств. И что самое интересное, никакой другой альтернативы для него пока не предвидится.
Думаю, что изложенной мною информации для начала вам будет вполне достаточно. А дальше, если возникнет такая потребность, каждый сможет углубиться в самостоятельное изучение этой темы.
Я же буду прощаться и после небольшого перерыва подготовлю для вас новую статью моего блога, на какую-нибудь интересную тему.
Источник
Зачем нужен двоичный код?
До появления ЭВМ использовались различные автоматические системы, принцип работы которых основан на получении сигнала. Срабатывает датчик, цепь замыкается и включается определенное устройство. Нет тока в сигнальной цепи – нет и срабатывания. Именно электронные устройства позволили добиться прогресса в обработке информации, представленной наличием или отсутствием напряжения в цепи.
Дальнейшее их усложнение привело к появлению первых процессоров, которые так же выполняли свою работу, обрабатывая уже сигнал, состоящий из импульсов, чередующихся определенным образом
Мы сейчас не будем вникать в программные подробности, но для нас важно следующее: электронные устройства оказались способными различать заданную последовательность поступающих сигналов. Конечно, можно и так описать условную комбинацию: «есть сигнал»; «нет сигнала»; «есть сигнал»; «есть сигнал»
Даже можно упростить запись: «есть»; «нет»; «есть»; «есть».
Безусловно, процессорная техника шагнула далеко вперед и сейчас чипы способны воспринимать не просто последовательность сигналов, а целые программы, записанные определенными командами, состоящими из отдельных символов.
Но для их записи используется все тот же двоичный код, состоящий из нулей и единиц, соответствующий наличию или отсутствию сигнала. Есть он, или его нет – без разницы. Для чипа любой из этих вариантов – это единичная частичка информации, которая получила название «бит» (bit — официальная единица измерения).
Условно, символ можно закодировать последовательностью из нескольких знаков. Двумя сигналами (или их отсутствием) можно описать всего четыре варианта: 00; 01;10; 11. Такой способ кодирования называется двухбитным. Но он может быть и:
- Четырехбитным (как в примере на абзац выше 1011) позволяет записать 2^4 = 16 комбинаций-символов;
- Восьмибитным (например: 0101 0011; 0111 0001). Одно время он представлял наибольший интерес для программирования, поскольку охватывал 2^8 = 256 значений. Это давало возможность описать все десятичные цифры, латинский алфавит и специальные знаки;
- Шестнадцатибитным (1100 1001 0110 1010) и выше. Но записи с такой длинной – это уже для современных более сложных задач. Современные процессоры используют 32-х и 64-х битную архитектуру;
Скажу честно, единой официальной версии нет, то так сложилось, что именно комбинация из восьми знаков стала стандартной мерой хранящейся информации, именуемой «байт». Таковая могла применяться даже к одной букве, записанной 8-и битным двоичным кодом. Итак, дорогие мои друзья, запомните пожалуйста (если кто не знал):
Так принято. Хотя символ, записанный 2-х или 32-х битным значением так же номинально можно назвать байтом. Кстати, благодаря двоичному коду мы можем оценивать объемы файлов, измеряемые в байтах и скорость передачи информации и интернета (бит в секунду).
Двоичное кодирование чисел
Сейчас в компьютерах числа представлены в закодированном виде, непонятном для обычного человека. Использование арабских цифр так, как мы себе представляем, для техники нерационально. Причиной тому является необходимость присваивать каждому числу свою неповторимый символ, что сделать порой невозможно.

Существуют две системы счисления: позиционная и непозиционная. Непозиционная система основана на использовании латинских букв и знакома нам в виде греческих цифр. Такой способ записи достаточно сложен для понимания, поэтому от него отказались.
Позиционная система счисления используется и сегодня. Сюда входит двоичное, десятичное, восьмеричное и даже шестнадцатеричное кодирование информации.
Десятичной системой кодирования мы пользуемся в быту. Это привычные для нас арабские цифры, которые понятны каждому человеку. Двоичное кодирование чисел отличается использованием только нуля и единицы.
Целые числа переводятся в двоичную систему кодирования путем деления их на 2. Полученные частные также поэтапно делятся на 2, пока не получится в итоге 0 или 1. Например, число 12310 в двоичной системе может быть представлено в виде 11110112. А число 2010 будет выглядеть как 101002.
Индексы 10 и 2 обозначаются, соответственно, десятичную и двоичную систему кодирования чисел. Символ двоичного кодирования используется для упрощения работы со значениями, представленными в разных системах счисления.
Методы программирования десятичных чисел основаны на “плавающей запятой”. Для того чтобы правильно перевести значение из десятичной в двоичную систему кодирования, используют формулу N = M х qp. М – это мантисса (выражение числа без какого-либо порядка), p – это порядок значения N, а q – основание системы кодирование (в нашем случае 2).
Не все числа являются положительными. Для того чтобы различить положительные и отрицательные числа, компьютер оставляет место в 1 бит для кодирования знака. Здесь ноль представляет знак плюс, а единица – минус.
Использование такой системы счисления упрощает для компьютера работу с числами. Вот почему двоичное кодирование является универсальным при вычислительных процессах.

Трактовка понятий
Человеческие мысли выражаются в виде текста, который состоит из слов. Подобное представление информации называется алфавитным, так как основа языка — алфавит. Он считается конечным набором различных знаков любой природы. Их используют для составления сообщений.
Вам известно что для обозначения количества мы пользуемся цифрами, для обозначения звуков на письме буквами. Можно сказать что цифры и буквы это коды. Одна и тажа информация может быть закодирована по разному. Например китайские и японские иероглифы являются символами которыми кодируется буква или слово. Основу любого языка составляет алфавит — конечный набор различных знаков (символов) любой природы, из которых складывается сообщение на данном языке. То есть символизация информации – это описание объектов или явлений с помощью символов того или иного алфавита. Под мощностью алфавита понимают количество символов, составляющий данный алфавит, что в свою очередь определяет количество возможных комбинаций (слов) которые можно составить из символов данного алфавита в соответствии с определенными правилами.
Чтобы зашифровать данные, необходимо знать правила записи кодов (условные обозначения информации). Понятие кодирование связано с преобразованием сообщений в комбинацию символов с учётом кодов. При общении люди используют русский либо другой национальный язык. В процессе разговора код передаётся звуками, а при письменном общении с помощью букв. У водителей или у пилотов обработка информации также осуществляется световыми сигналами, специальнвми символами — знаками.
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Метод координат
Любые данные можно передать с помощью двоичных чисел, в том числе и графические изображение, представляющие собой совокупность точек. Чтобы установить соответствие чисел и точек в бинарном коде, используют метод координат.
Метод координат на плоскости основан на изучении свойств точки в системе координат с горизонтальной осью Ox и вертикальной осью Oy. Точка будет иметь 2 координаты.
Если через начало координат проходит 3 взаимно перпендикулярные оси X, Y и Z, то используется метод координат в пространстве. Положение точки в таком случае определяется тремя координатами.
 Система координат в пространстве
Система координат в пространстве
Представление звуковой информации в компьютере
Звук представляет собой непрерывный сигнал — звуковую волну с меняющейся амплитудой и частотой. Чем больше амплитуда сигнала, тем он громче для человека. Чем больше частота сигнала, тем выше тон. Частота звуковой волны выражается числом колебаний в секунду и измеряется в герцах (Гц, Hz). Человеческое ухо способно воспринимать звуки в диапазоне от 20 Гц до 20 кГц, который называют звуковым.
Количество бит, отводимое на один звуковой сигнал, называют глубиной кодирования звука. Современные звуковые карты обеспечивают 16-, 32- или 64-битную глубину кодирования звука.
При кодировании звуковой информации непрерывный сигнал заменяется дискретным, то есть превращается в последовательность электрических импульсов (двоичных нулей и единиц)
Важной характеристикой при кодировании звука является частота дискретизации — количество измерений уровней сигнала за 1 секунду:- 1 (одно) измерение в секунду соответствует частоте 1 Гц;
— 1000 измерений в секунду соответствует частоте 1 кГц.. Количество измерений может лежать в диапазоне от 8 кГц до 48 кГц (от частоты радиотрансляции до частоты, соответствующей качеству звучания музыкальных носителей).
Количество измерений может лежать в диапазоне от 8 кГц до 48 кГц (от частоты радиотрансляции до частоты, соответствующей качеству звучания музыкальных носителей).
Существуют различные методы кодирования звуковой информации двоичным кодом, среди которых можно выделить два основных направления: метод FM и метод Wave-Table.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, и следовательно, может быть описан кодом. Разложение звуковых сигналов в гармонические ряды и представление в виде дискретных цифровых сигналов (рис. 1.5) выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП).

Рис. 1.5. Преобразование звукового сигнала в дискретный сигнал: a — звуковой сигнал на входе АЦП; б — дискретный сигнал на выходе АЦП
Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). Процесс преобразования звука представлен на рис. 1.6. Данный метод кодирования не дает хорошего качества звучания, но обеспечивает компактный код.

Рис 1.6. Преобразование дискретного сигнала в звуковой сигнал: а — дискретный сигнал на входе ЦАП; б — звуковой сигнал на выходе ЦАП
Таблично-волновой метод (Wave-Table) основан на том, что в заранее подготовленных таблицах хранятся образцы звуков окружающего мира, музыкальных инструментов и т. д.. Числовые коды выражают высоту тона, продолжительность и интенсивность звука и прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Звуковые файлы имеют несколько форматов. Наиболее популярные из них MIDI, WAV, МРЗ.
Формат MIDI (Musical Instrument Digital Interface) изначально был предназначен для управления музыкальными инструментами. В настоящее время используется в области электронных музыкальных инструментов и компьютерных модулей синтеза.
Формат аудиофайла WAV (waveform) представляет произвольный звук в виде цифрового представления исходного звукового колебания или звуковой волны. Все стандартные звуки Windows имеют расширение WAV.
Формат МРЗ (MPEG-1 Audio Layer 3) — один из цифровых форматов хранения звуковой информации. Он обеспечивает более высокое качество кодирования.
1.3. Методы хранения и передачи информации
Хранение и передача информации осуществляются за счет преобразования
информации в удобную форму в зависимости от условий, в которых находятся
источник и потребитель информации. Передача информации может осуществляться
напрямую, а также за счет усиления сигнала (рупор, локальная компьютерная
сеть, письменная речь и т. д.) или же путем преобразования сигнала и
передачи его на далекие расстояния (телефон, телеграф, радио, телевидение,
глобальные компьютерные сети и т. д.).
Хранение информации осуществляется на долговременных носителях: камень,
пергамент, кожа, бумага, магнитные носители, лазерные диски, серверы
вычислительных сетей и т. п. При этом передача освобождается от гнета
реального времени, становятся возможными даже сообщения человека самому
себе (заметки на память). Таким образом за счет использования «инструмента»
уменьшается нагрузка на человеческую память. В настоящее время основным
средством хранения информации является персональный компьютер (ПК) и
другие средства вычислительной техники.
Процедура хранения информации в ПК состоит
в том, чтобы сформировать и поддерживать структуру хранения данных в
памяти компьютера. Современные структуры хранения данных должны быть
независимы от программ, использующих эти данные, и реализовывать принципы
полноты и минимальной избыточности. Такие структуры получили название
«базы данных». Процедуры создания структуры хранения (базы
данных), актуализации, извлечения и удаления данных производятся при
помощи специальных программ, называемых «системы управления базами
данных».
Процедура актуализации данных позволяет изменить значения данных,
записанных в базе, либо дополнить определенный раздел, группу данных.
Устаревшие данные могут быть удалены с помощью соответствующей операции.
Процедура извлечения данных необходима для пересылки из базы
данных необходимых сведений либо для преобразования, либо для отображения,
либо для передачи по вычислительной сети.
Хранение и передача данных тесно связаны между собой, для выполнения
этих процедур используют сетевые информационные технологии. Программы,
предназначенные только для хранения и передачи данных, носят название
«информационные хранилища» и представляют собой компьютеризированные
архивы.
Представление и устройство памяти персонального компьютера
Скорее всего, вы знаете, что внутренняя память компьютера состоит из двух частей – оперативной и основной:
Чтобы иметь представление, как работает внутренняя память компьютера, и как её использовать, нужно заглянуть внутрь системного блока. Здесь можно провести аналогию с тетрадным листом “в клеточку”. Каждая клетка содержит в себе одно из двух состояний – 0 или 1. Если в ячейке стоит 1, то это говорит о том, что данная ячейка внутренней памяти включена, если 0, то выключена. Этот способ представления информации называется цифровым кодированием.
Каждая ячейка внутренней памяти ПК хранит в себе единицу информации, которая называется битом. Составляя различные последовательности из битов, мы можем определить различную информацию. У цифрового кодирования много преимуществ – легко копировать и переносить материалы с одного носителя на другой. При создании дубликата копия полностью идентична оригиналу, что невозможно осуществить с данными, которые представлены в аналоговой форме. Из-за большого количества преимуществ в 80-х годах 20 века люди начали использовать способы представления текста, звука и фото с помощью цифр.
1.4. Обработка информации. Двоичная система счисления
Источниками и носителями информации могут быть сигналы любой природы:
речь, музыка, текст, показания приборов и т. д. Однако хранение, передача
и переработка информации в ее естественном физическом виде большей частью
неудобна, а иногда и просто невозможна. В таких случаях применяется
кодирование.
Кодирование — это процесс установления взаимно
однозначного соответствия элементам и словам одного алфавита элементов
и слов другого алфавита.
Кодом называется правило, по которому сопоставляются различные
алфавиты и слова.
Всю информацию, участвующую в электронном вычислительном процессе,
можно разделить на обрабатываемую (данные) и управляющую (программы).
В схеме преобразования информации в данные (рис. 1) представлены проводимые
над информацией и данными процессы, которые образуются после введения
информации в компьютер. Также представлены процедуры и связи между ними,
с помощью которых осуществляются эти процессы.
Процедура отображения — преобразование информации в вид, удобный
для восприятия человеком.
Практически всегда основой кодирования чисел в современной ЭВМ является
двоичная система счисления.
Системой счисления называется способ записи
чисел при помощи ограниченного числа символов (цифр).
Позиционной системой счисления называется система счисления,
при которой число, связанное с цифрой, зависит от места, которое она
занимает.
Рис. 1. Схема преобразования информации в данные и действий над ними
Пример. Перевести в десятичную запись число (10000111)2.
Перевести в двоичную запись число 89. Сложить в двоичной записи эти
два числа, результат перевести в десятичную запись.
Решение:
(10000111)2 =1·27
+ 1·22 + 1·21
+ 1·2 = 128 + 4 + 2 + 1 =
(135)10,
(89)10 = 1·26
+ 1·24 + 1·23
+ 1·2 = (1011001)2,
| 10000111 |
| + 1011001 |
| 11100000, |
(11100000)2 =128+64+32=(224)10.
Компьютер – основной инструмент работы с текстом
В современном мире компьютер – уникальное устройство, в том числе и для работы с текстовой информацией. Элементарные программы для текстовых документов имеют возможность создания текстов, составленных из символов, печатаемых с клавиатуры, и небольшой комплект инструментов для оформления информации. Для подготовки наиболее сложных текстов с графиками, табличным представлением данных, надписями, схемами, картинками и фотографиями целесообразно использование сильных текстовых процессоров.
Среди множества программ, предназначенных для работы с текстовой информацией, выделяют следующие:
- Foxit Reader – бесплатная программа для открытия текстовых документов в формате PDF. Кроме просмотра, она имеет возможность редактировать и отправлять текст на печать.

- Libre Office Writer– свободное офисное приложение. Прямой аналог Open Office Writer.Текстовый документа, напечатанный в этой программе, будет иметь формат ODF.
- Adobe Reader – удобная программа для работы текстовыми документами в формате PDF, используемого для создания текстовой информации высокого качества.
- Open Office Writer– бесплатное программное обеспечение, полная альтернатива приложению Microsoft Office Word. Поддерживает многие форматы. Из минусов данного приложения – отсутствует автоматическая проверка грамматики.
- Word Pad – стандартная программа операционной системы Microsoft Windows, обладающая ограниченными функциональными возможностями.

- В большинстве случаев для создания текстового документа используют программу Microsoft Word, имеющую богатый арсенал инструментов для обработки текстовой информацией. Позволяет создавать документы различной сложности.
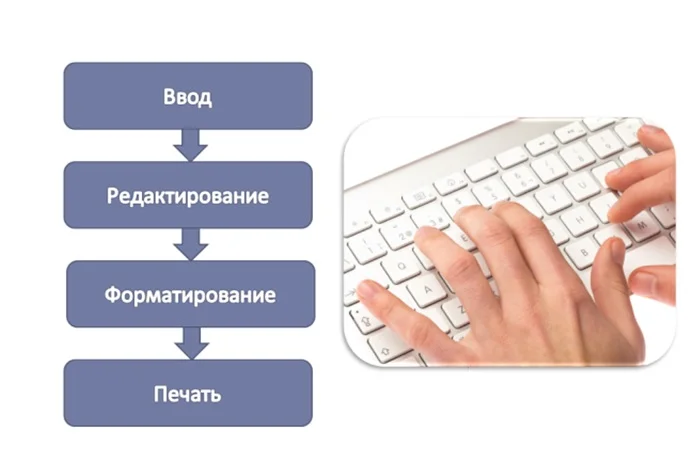
Основные стадии подготовки электронного текстового документа:
- Ввод (набор символов).
- Редактирование.
- Форматирование.
- Печать.

§ 2.1. Кодирование текстовой информации
Содержание урока
Кодирование текстовой информации
Кодирование текстовой информации
Двоичное кодирование текстовой информации в компьютере.
Информация, выраженная с помощью естественных и формальных языков в письменной форме, обычно называется текстовой информацией.
Для представления текстовой информации (прописные и строчные буквы русского и латинского алфавитов, цифры, знаки и математические символы) достаточно 256 различных знаков. По формуле (1.1) можно вычислить, какое количество информации необходимо, чтобы закодировать каждый знак:
N = 2I ⇒ 256 = 2I ⇒ 28 = 2I ⇒ I = 8 битов.
Для обработки текстовой информации в компьютере необходимо представить ее в двоичной знаковой системе. Для кодирования каждого знака требуется количество информации, равное 8 битам, т. е. длина двоичного кода знака составляет восемь двоичных знаков. Каждому знаку необходимо поставить в соответствие уникальный двоичный код в интервале от 00000000 до 11111111 (в десятичном коде от 0 до 255) (табл. 2.1).
Человек различает знаки по их начертанию, а компьютер — по их двоичным кодам. При вводе в компьютер текстовой информации происходит ее двоичное кодирование. Пользователь нажимает на клавиатуре клавишу со знаком, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код знака). Код знака хранится в оперативной памяти компьютера, где занимает одну ячейку (размером 1 байт).
В процессе вывода знака на экран компьютера производится обратное кодирование, т. е. преобразование двоичного кода знака в его изображение.
Таблица 2.1. Кодировки знаков>

Различные кодировки знаков. Присвоение знаку конкретного двоичного кода — это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода в кодовой таблице (десятичные коды с 0 по 32) соответствуют не знакам, а операциям (перевод строки, ввод пробела и т. д.).
Десятичные коды с 33 по 127 являются интернациональными и соответствуют знакам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Десятичные коды с 128 по 255 являются национальными, т. е. в различных национальных кодировках одному и тому же коду соответствуют разные знаки. К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (Windows, MS-DOS, КОИ-8, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
В последние годы широкое распространение получил новый международный стандарт кодирования текстовых символов Unicode, который отводит на каждый символ 2 байта (16 битов). По формуле (1.1) определим количество символов, которые можно закодировать:
N = 2I = 216 = 65 536.
Такого количества символов оказалось достаточно, чтобы закодировать не только русский и латинский алфавиты, цифры, знаки и математические символы, но и греческий, арабский, иврит и другие алфавиты.
Итак, в настоящее время имеется шесть различных кодировок для букв русского алфавита, в которых один и тот же знак имеет различные коды (табл. 2.2). К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в операционную систему и приложения.
Таблица 2.2. Десятичные коды некоторых знаков в различных кодировках
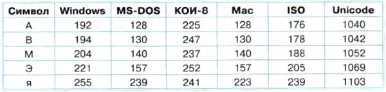
Например, в кодировке Windows последовательность числовых кодов 221 194 204 образует слово «ЭВМ» (см. табл. 2.2), тогда как в других кодировках это будет бессмысленный набор символов.
Контрольные вопросы
1. Почему при кодировании текстовой информации в компьютере в большинстве кодировок используется 256 различных символов, хотя русский алфавит включает только 33 буквы?
2. С какой целью ввели кодировку Unicode, которая позволяет закодировать 65 536 различных символов? Подготовьте сообщение.
Задания для самостоятельного выполнения
2.1. Задание с кратким ответом. В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке. Определите объем текстовой информации, занимающей весь экран монитора, в кодировке Unicode.
2.2. Задание с развернутым ответом. Пользователь компьютера, хорошо владеющий навыками ввода информации с клавиатуры, может вводить в минуту 100 знаков. Какое количество информации может ввести пользователь в компьютер за одну минуту в кодировке Windows? В кодировке Unicode?
Cкачать материалы урока