

Краткое объяснение кодирования текстовой информации. Информатика
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Кодирование графической информации
Общие понятия о графической информации
Графическая информация представляет собой изображение, сформированное из определенного числа точек – пикселей. Добавим к этой информации новые сведения. Процесс разбиения изображения на отдельные маленькие фрагменты (точки) называется пространственной дискретизацией. Ее можно сравнить с построением рисунка из мозаики. При этом каждой мозаике (точке) присваивается код цвета.
От количества точек зависит качество изображения. Оно тем выше, чем меньше размер точки и соответственно большее их количество составляет изображение. Такое количество точек называется разрешающей способностью и обычно существуют четыре основных значений этого параметра: 640×480, 800×600, 1024×768, 1280×1024.
Качество изображения зависит также от количества цветов, т.е. от количества возможных состояний точек изображения, т.к. при этом каждая точка несет большее количество информации. Используемый набор цветов образует палитру цветов.
Кодирование цвета
Рассмотрим, каким образом происходит кодирование цвета точек. Для кодирования цвета применяется принцип разложения цвета на составляющие. Их три: красный цвет (Red, R), синий (Blue, В) и зелёный (Green, G). Смешивая эти составляющие, можно получать различные оттенки и цвета – от белого до черного.
Сколько бит необходимо выделить для каждой составляющей, чтобы при кодировании изображения его качество было наилучшим?
Если рисунок черно-белый, то общепринятым на сегодняшний день считается представление его в виде комбинации точек с 256 градациями серого, т.е. для кодирования точки достаточно 1 байта.
Если же изображение цветное, то с помощью 1 байта можно также закодировать 256 разных оттенков цветов. Этого достаточно для рисования изображений типа тех, что мы видим в мультфильмах. Для изображений же живой природы этого недостаточно. Если увеличить количество байт до двух (16 бит), то цветов станет в два раза больше, т.е. 65536. Это уже похоже на то, что мы видим на фотографиях и на картинках в журналах, но все равно хуже, чем в живой природе. Увеличим еще количество байтов до трех (24 бита). В этом случае можно закодировать 16,5 миллионов различных цветов. Именно такой режим позволяет работать с изображениями наилучшего качества.
Количество бит, необходимое для кодирования цвета точки называется глубиной цвета. Наиболее распространенными значениями глубины цвета являются 4, 8, 16 и 24 бита на точку.
Решение задач
1. Какой объём видеопамяти необходим для хранения четырёх страниц изображения при условии, что разрешающая способность дисплея равна 640Х480 точек, а используемых цветов – 32?
Теперь все параметры нам известны, находим объём:
V = 640*480*5*4 =6144000 бит = 750 Кбайт (т.к. в 1 байте – 8 бит и в 1 Кбайте – 1024 байт)Ответ: 750 Кбайт
2. 256-цветный рисунок содержит 1 Кбайт информации. Из скольки точек он состоит?
Переведём известный объём в биты: 1Кбайт = 1024 байт*8бит = 8192 бит
Зная глубину и объём находим количество точек на изображении: 8192:8 = 1024 точек
Как перевести любое слово в двоичный код???
С помощью таблицы ASCII, ее легко найти в Интернете по названию. В таблице, правда, обычно коды представляют для краткости в шестнадцатеричном виде, каждая цифра шестнадцатеричного кода — четыре двоичных цифры, таблицу перевода шестнадцатеричных цифр в двоичные легко найти, а имеющие дело с программированием обычно помнят ее наизусть. Каждому символу соответствует определенный код, код слова — последовательность кодов составляющих его символов.
Очень просто: у всех букв дано есть присвоенный им двоичный код, если правильно помню — то латинское «а» имеет код 101. И так далее…
имеется в виду СЛОВО=ТЕКСТ?
Тогда есть разные кодовые таблицы. Например ASCII.
<a rel=»nofollow» href=»http://ru.wikipedia.org/wiki/ASCII» target=»_blank»>http://ru.wikipedia.org/wiki/ASCII</a>
По ней определяем код каждого символа и переводим в двоичную систему.
пример:
Alex=41,6C,65,78=1000001 1101100 1100101 1110101
Числовое кодирование текстовой информации
В каждом национальном языке имеется свой алфавит, который состоит из определенного набора букв, следующих друг за другом, а значит и имеющих свой порядковый номер.
Каждой букве сопоставляется целое положительное число, которое называют кодом символа. Именно этот код и будет хранить память компьютера, а при выводе на экран или бумагу преобразовывать в соответствующий ему символ. Помимо кодов самих символов в памяти компьютера хранится и информация о том, какие именно данные закодированы в конкретной области памяти. Это необходимо для различия представленной информации в памяти компьютера (числа и символы).
Используя соответствия букв алфавита с их числовыми кодами, можно сформировать специальные таблицы кодирования. Иначе можно сказать, что символы конкретного алфавита имеют свои числовые коды в соответствии с определенной таблицей кодирования.
Однако, как известно, алфавитов в мире большое множество (английский, русский, китайский и др.). Соответственно возникает вопрос, каким образом можно закодировать все используемые на компьютере алфавиты.
Чтобы ответить на данный вопрос, нам придется заглянуть назад в прошлое.
В $60$-х годах прошлого века в американском национальном институте стандартизации (ANSI) была разработана специальная таблица кодирования символов, которая затем стала использоваться во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange, что означает в переводе с английского «американский стандартный код для обмена информацией»).
В данной таблице представлен $7$-битный стандарт кодирования, при использовании которого компьютер может записать каждый символ в одну $7$-битную ячейку запоминающего устройства. При этом известно, что в ячейке, состоящей из $7$ битов, можно сохранять $128$ различных состояний. В стандарте ASCII каждому из этих $128$ состояний соответствует какая-то буква, знак препинания или же специальный символ.
В процессе развития вычислительной техники стало ясно, что $7$-битный стандарт кодирования достаточно мал, поскольку в $128$ состояниях $7$-битной ячейки нельзя закодировать буквы всех письменностей, имеющихся в мире.
Чтобы решить эту проблему, разработчики программного обеспечения начали создавать собственные 8-битные стандарты кодировки текста. За счет дополнительного бита диапазон кодирования в них был расширен до $256$ символов. Во избежание путаницы, первые $128$ символов в таких кодировках, как правило, соответствуют стандарту ASCII. Оставшиеся $128$ — реализуют региональные языковые особенности.
Замечание 3
Как мы знаем национальных алфавитов огромное количество, поэтому и расширенные таблицы ASCII-кодов представлены множеством вариантов. Так для русского языка существует также несколько вариантов, наиболее распространенные Windows-$1251$ и Koi8-r. Большое количество вариантов кодировочных таблиц создает определенные трудности. К примеру, мы отправляем письмо, представленное в одной кодировке, а получатель при этом пытается прочесть его в другой. В результате на экране у него появляется непонятная абракадабра, что говорит о том, что получателю для прочтения письма требуется применить иную кодировочную таблицу.
Существует и другая проблема, которая заключается в том, что алфавиты некоторых языков содержат слишком много символов, которые не позволяют помещаться им в отведенные позиции с $128$ до $255$ однобайтовой кодировки.
Следующая проблема возникает тогда, когда в тексте используют несколько языков (например, русский, английский и немецкий). Нельзя же использовать обе таблицы сразу.







Для решения этих проблем в начале $90$-х годов прошлого столетия был разработан новый стандарт кодирования символов, который назвали Unicode. С помощью этого стандарта стало возможным использование в одном тексте любых языков и символов.
Данный стандарт для кодирования символов предоставляет $31$ бит, что составляет $4$ байта за минусом $1$ бита. Количество возможных комбинаций при использовании данной кодировочной таблицы очень велико: $231 = 2 \ 147 \ 483 \ 684$ (т.е. более $2$ млрд.). Это возможно стало в связи с тем, что Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и другие специальные символы. И все-таки информационная емкость $31$-битового Unicode слишком велика, И как следствие, наиболее часто используют именно сокращенную $16$-битовую версию ($216 = 65 \ 536$ значений), в которой представлены все современные алфавиты.
В Unicode первые $128$ кодов совпадают с таблицей ASCII.
Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Источник
Как происходит кодирование текстовой информации
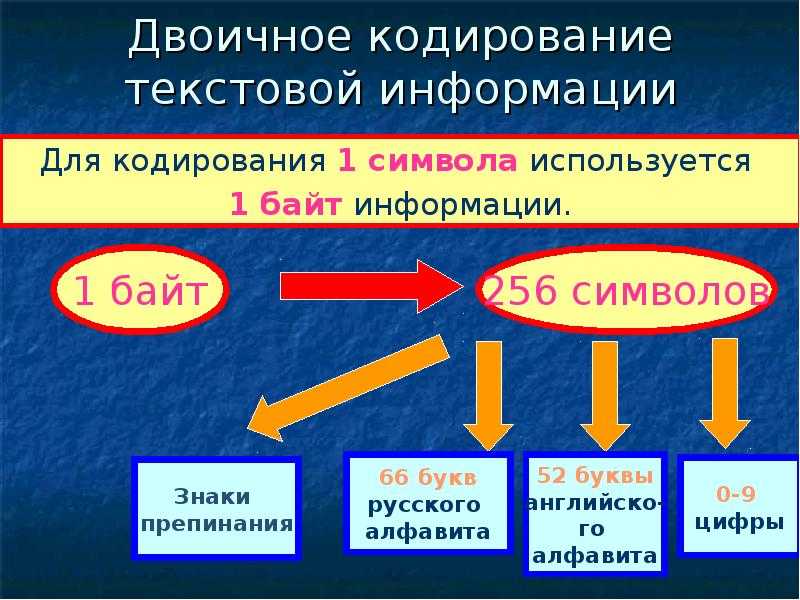
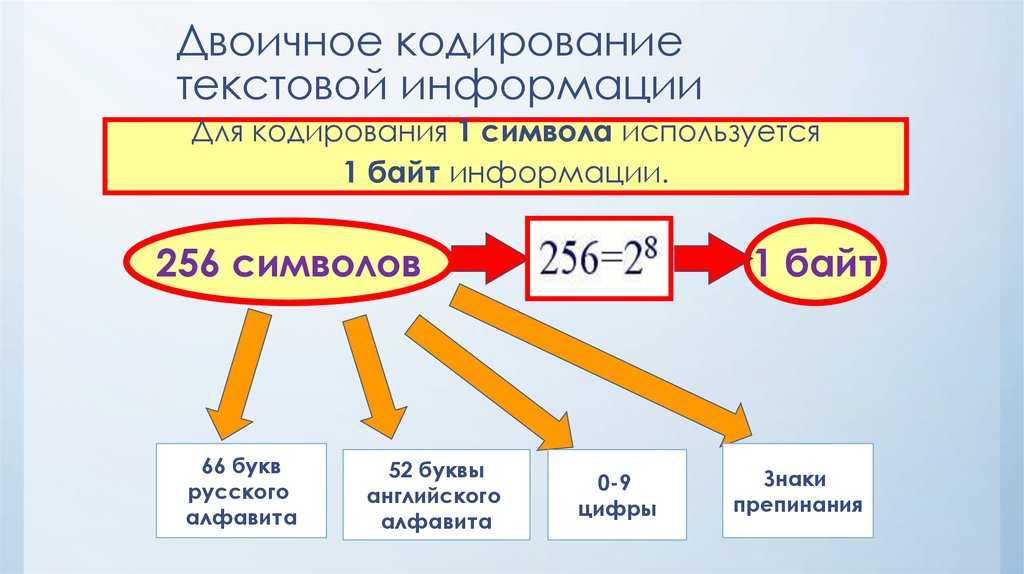
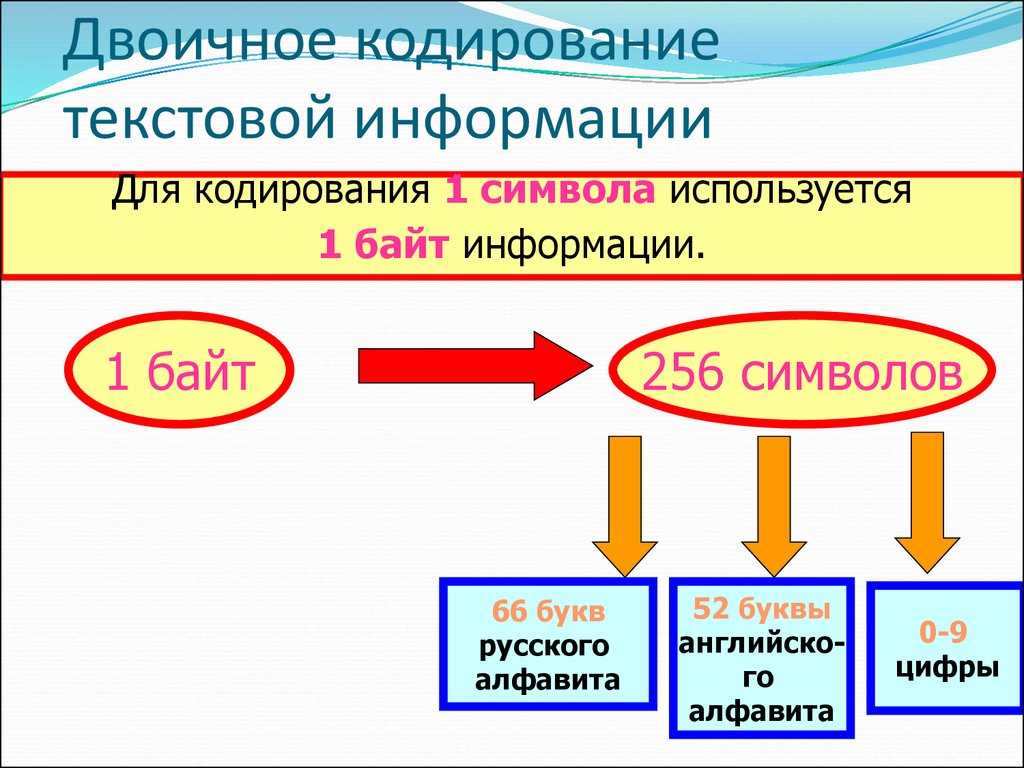
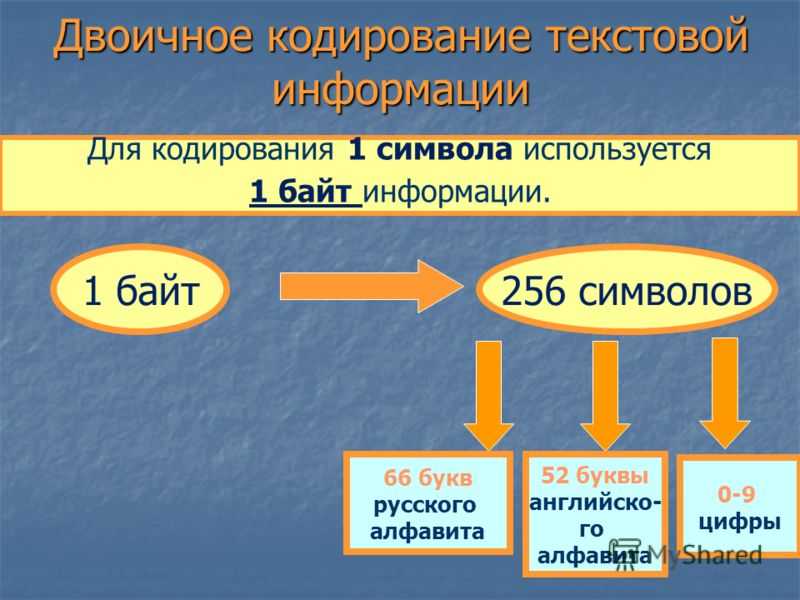
В русском языке 33 буквы и, значит, для их кодирования надо 33 байта. Компьютер различает большие (заглавные) и маленькие (строчные) буквы, только если они кодируются различными кодами. Значит, чтобы закодировать большие и маленькие буквы русского алфавита, потребуется 66 байт.
А дальше дело осталось за малым. Надо сделать так, чтобы все люди на Земле договорились между собой о том, какие именно коды (с 0 до 255, т.е. всего 256) присвоить символам. Допустим, все люди договорились, что код 33 означает восклицательный знак (!), а код 63 – вопросительный знак (?). И так же – для всех применяемых символов. Тогда это будет означать, что текст, набранный одним человеком на своем компьютере, всегда можно будет прочитать и распечатать другому человеку на другом компьютере.
10000000 — 11111111
Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
Первая половина таблицы кодов ASCII
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
UTF — универсальная кодировка для хранения символов
Юникод как таковой отвечает на вопрос «Как мы храним символы?». Он объясняет, каким символам мы присваиваем какие коды; по какому принципу выделяем эти коды; какие символы используем, а какие нет.
Но также нам нужно знать, как хранить и передавать данные о символах Юникода. Вот это и есть UTF.
UTF (Unicode Transformation Format) — это стандарт кодирования символов Unicode. Разберём на куски:
- Стандарт — то есть всеобщая договорённость. Разработчик в России и Мексике открывают одну и ту же документацию и одинаково понимают, как им работать с данными. Договорились такие.
- Кодирование — то есть как мы представляем эти данные на компьютере. Это одно большое число? Несколько чисел поменьше? Сколько байтов выделять на эти символы? Нужно ли специально говорить компьютеру, что сейчас будут символы Юникода?
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Двоичное кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации.
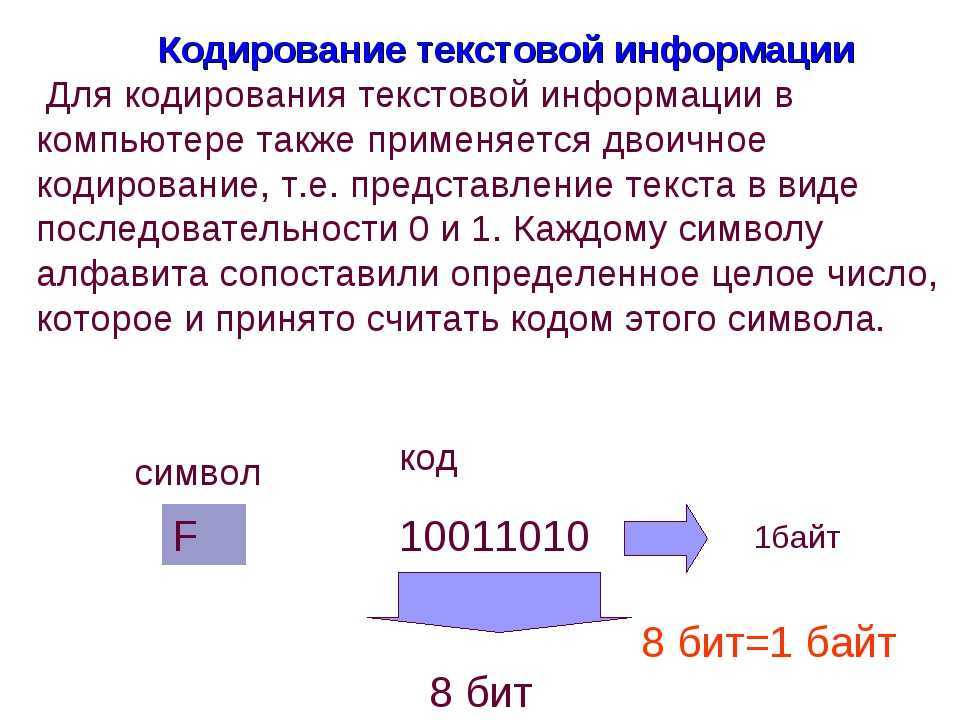
Традиционно для кодирования одного символа используется количество информации = 1 байту (1 байт = 8 битов).
Для кодирования одного символа требуется один байт информации.
Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. (28= 256)
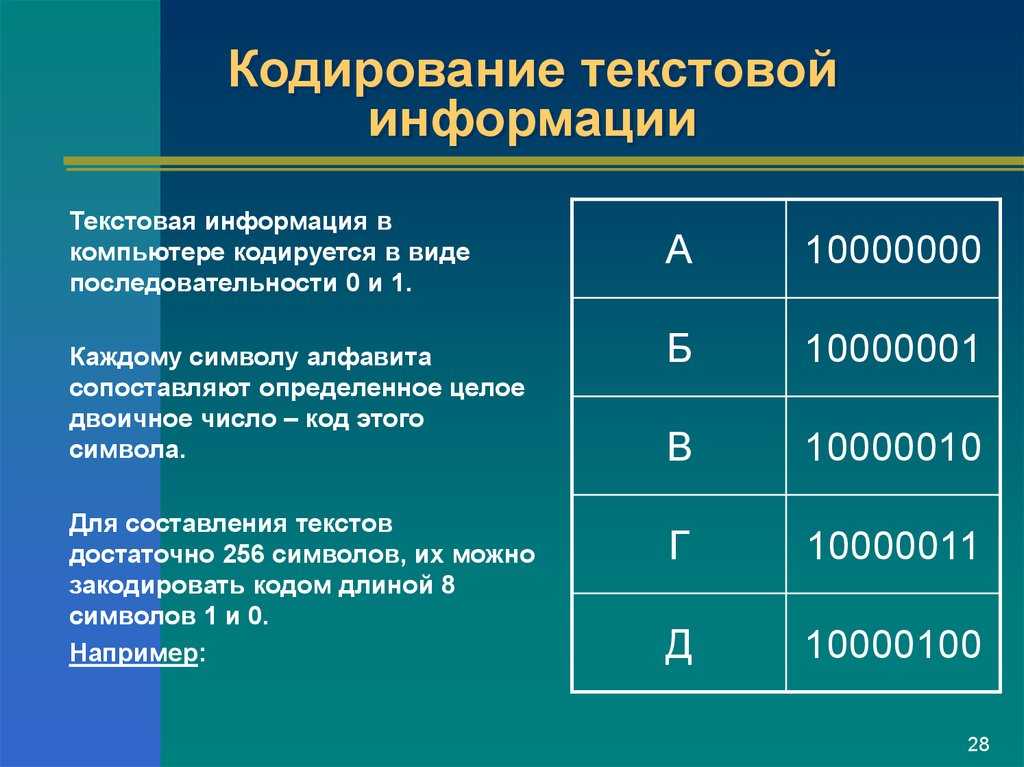
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255).
Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей. Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера (коды), называется таблицей кодировки
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера (коды), называется таблицей кодировки.
Для разных типов ЭВМ используются различные кодировки. С распространением IBM PC международным стандартом стала таблица кодировкиASCII(AmericanStandardCode forInformationInterchange) – Американский стандартный код для информационного обмена.








Стандартной в этой таблице является только первая половина, т.е. символы с номерами от 0 (00000000) до 127 (0111111). Сюда входят буква латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы.
Остальные 128 кодов используются в разных вариантах. В русских кодировках размещаются символы русского алфавита.
В настоящее время существует 5 разных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO).
В настоящее время получил широкое распространение новый международный стандартUnicode, который отводит на каждый символ два байта. С его помощью можно закодировать 65536 (216= 65536 ) различных символов.
Таблица расширенного кода ASCII (один из вариантов)
Сегодня очень многие люди для подготовки писем, документов, статей, книг и пр. используют компьютерные текстовые редакторы. Компьютерные редакторы, в основном, работают с алфавитом размером 256 символов.
В этом случае легко подсчитать объем информации в тексте. Если 1 символ алфавита несет 1 байт информации, то надо просто сосчитать количество символов; полученное число даст информационный объем текста в байтах.
Пусть небольшая книжка, сделанная с помощью компьютера, содержит 150 страниц; на каждой странице — 40 строк, в каждой строке — 60 символов. Значит страница содержит 40×60=2400 байт информации. Объем всей информации в книге: 2400 х 150 = 360 000 байт.
Обратите внимание!Цифры кодируются по стандарту ASCII в двух случаях – при вводе-выводе и когда они встречаются в тексте. Если цифры участвуют в вычислениях, то осуществляется их преобразование в другой двоичных код
Возьмем число 57.
При использовании в тексте каждая цифра будет представлена своим кодом в соответствии с таблицей ASCII. В двоичной системе это – 00110101 00110111.
При использовании в вычислениях, код этого числа будет получен по правилам перевода в двоичную систему и получим – 00111001.
Кодирование графики
Кодирование текстовой и графической информации имеет некоторые схожие моменты. Как известно, для вывода графической информации используется периферийное устройство компьютера под названием “монитор”. Графика сейчас (речь идет сейчас именно о компьютерной графике) широко используется в самых разных сферах. Благо, аппаратные возможности персональных компьютеров позволяют решать достаточно сложные графические задачи.
Обрабатывать видеоинформацию стало возможным в последние годы. Но текст при этом значительно “легче” графики, что, в принципе, понятно. Из-за этого конечный размер файлов графики необходимо увеличивать. Преодолеть подобные проблемы можно, зная суть, в которой представляется графическая информация.
Давайте для начала разберемся, на какие группы подразделяется данный вид информации. Во-первых, это растровая. Во-вторых, векторная.
Растровые изображения достаточно схожи с клетчатой бумагой. Каждая клетка на такой бумаге закрашивается тем или иным цветом. Такой принцип чем-то напоминает мозаику. То есть получается, что в растровой графике изображение разбивается на отдельные элементарные части. Их именуют пикселями. В переводе на русский язык пиксели обозначают “точки”. Логично, что пиксели упорядочены относительно строк. Графическая сетка состоит как раз из определенного количества пикселей. Ее также называют растром
Принимая во внимание эти два определения, можно сказать, что растровое изображение является не чем иным, как набором пикселей, которые отображаются на сетке прямоугольного типа
Проблема нулевых байтов
Сейчас немного информатики, потерпите.
Компьютер кодирует числа с помощью единиц и нулей в двоичной системе счисления. Она позволяет закодировать любое число, если дать ей достаточно места в памяти. Эти места измеряются в битах. Одним битом можно закодировать 0 или 1; двумя битами — числа от 0 до 3; восемью битами — от 0 до 255 и так далее. Биты слишком мелкие, поэтому для удобства хранения и обработки компьютеры группируют их по 8 бит, это называется байтом. В памяти можно выделять только байты, а не отдельные биты.
Максимальное количество символов в Юникоде — 1 112 064. Для хранения числа такого размера нам нужен 21 бит. Получается, что кодировка должна уметь работать с 21-битными числами.
Самое простое решение — выделить на каждый символ по 3 байта, то есть 24 бита. Например, символ с номером 998 536 в двоичной системе счисления выглядит так:
11110011110010001000
Если мы разобьём это на три байта и добавим впереди нужное количество нулей до трёх байтов, то получится такое:
00001111 00111100 10001000
Кажется, что мы сразу нашли способ кодирования: просто выделяй на все символы по три байта и кайфуй.
Но что, если нам нужен, например, символ под номером 150?
150₁₀ = 10010110₂
Разобьем снова на три байта:
00000000 00000000 10010110
У нас получилось в самом начале два нулевых байта. Проблема в том, что многие системы передачи данных воспринимают нулевые байты как конец передачи. Если они встретят такую последовательность, то решат, что передача окончена, а всё, что идёт дальше, — лишний шум, который обрабатывать не нужно. Если в нашем Юникод-тексте много символов из начала таблицы (например, всё на английском), то с чтением такого файла возникнут проблемы.









Чтобы выйти из этой ситуации, придумали UTF-8 — кодировку с плавающим количеством символов.
Базовая таблица кодировки ASCII
| 32 пробел | 48 0 | 64 @ | 80 P | 96 ` | 112 p |
| 33 ! | 49 1 | 65 A | 81 Q | 97 a | 113 q |
| 34 “ | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 T | 100 d | 116 t |
| 37 % | 53 5 | 69 E | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 H | 88 X | 104 h | 120 x |
| 41 ) | 57 9 | 73 I | 89 Y | 105 i | 121 y |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 { |
| 44 , | 60 < | 76 L | 92 \ | 108 l | 124 | |
| 45 — | 61 = | 77 M | 93 ] | 109 m | 125 } |
| 46 . | 62 > | 78 N | 94 ^ | 110 n | 126 ~ |
| 47 / | 63 ? | 79 O | 95 _ | 111 o | 127 |
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы: