
Криптография
В особых случаях возникает необходимость в засекречивании информации, содержащейся в сообщениях или документации. Это нужно для того чтобы она не была прочтена сторонними людьми. Такое кодирование текста именуется защитой данных от несанкционированного доступа, при которой секретный текст зашифровывается. В далеком прошлом пытались скрывать данные посредством тайнописи.
Под шифрованием подразумевается процесс, при котором открытый текст преобразуется в зашифрованный. Дешифрование является полностью обратным процессом преобразования, цель которого — восстановление исходного текста. Шифрование тоже является кодированием, но с использованием засекреченного метода, известного лишь источнику данных и их получателю. Есть целая наука о методах шифрования, известная как криптография.
Криптография — это наука, изучающая принципы и методы передачи и приема данных, зашифрованных посредством специальных ключей. Ключи — это секретные данные, применяемые при шифровке и расшифровке информации.
Не нашли ответ?
Просто напиши,с чем тебе нужна помощь
Мне нужна помощь
Презентация на тему: » Двоичное кодирование информации в компьютере. Двоичный код Вся информация, которую обработает компьютер, должна быть представлена двоичным кодом с помощью.» — Транскрипт:
1
Двоичное кодирование информации в компьютере

2
Двоичный код Вся информация, которую обработает компьютер, должна быть представлена двоичным кодом с помощью двух цифр – 0 и 1. Эти два символа 0 и 1 принято называть битами (от англ. binary digit – двоичный знак). Вид информации Двоичный код Числовая Текстовая Графическая Звуковая Видео

3
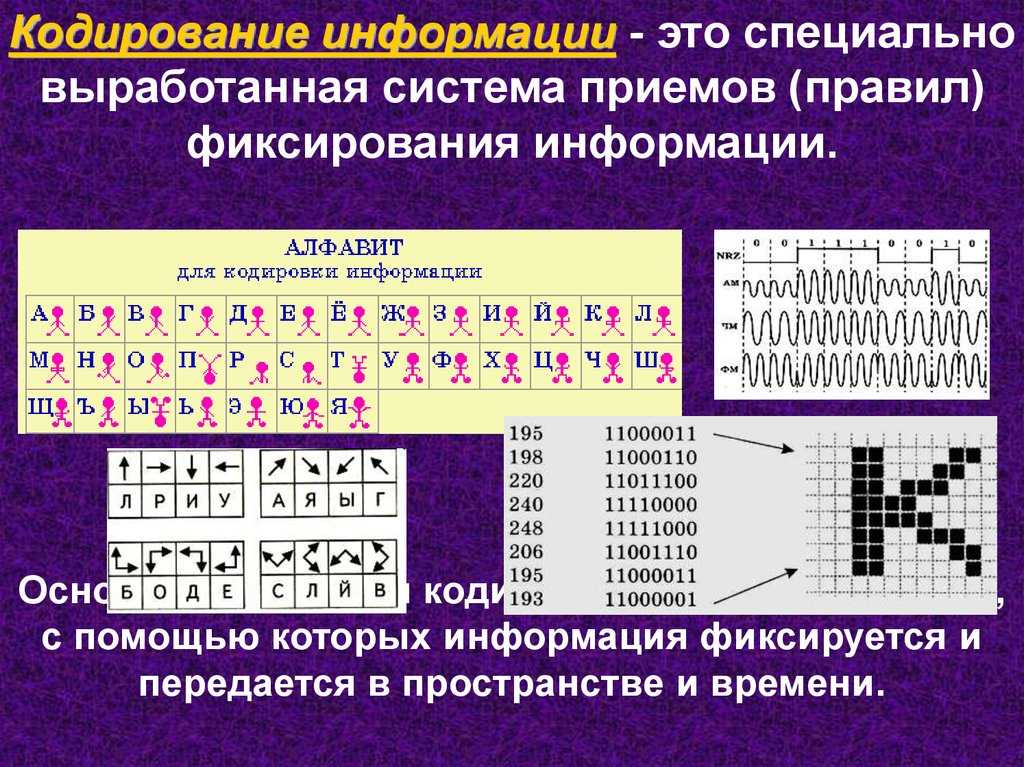
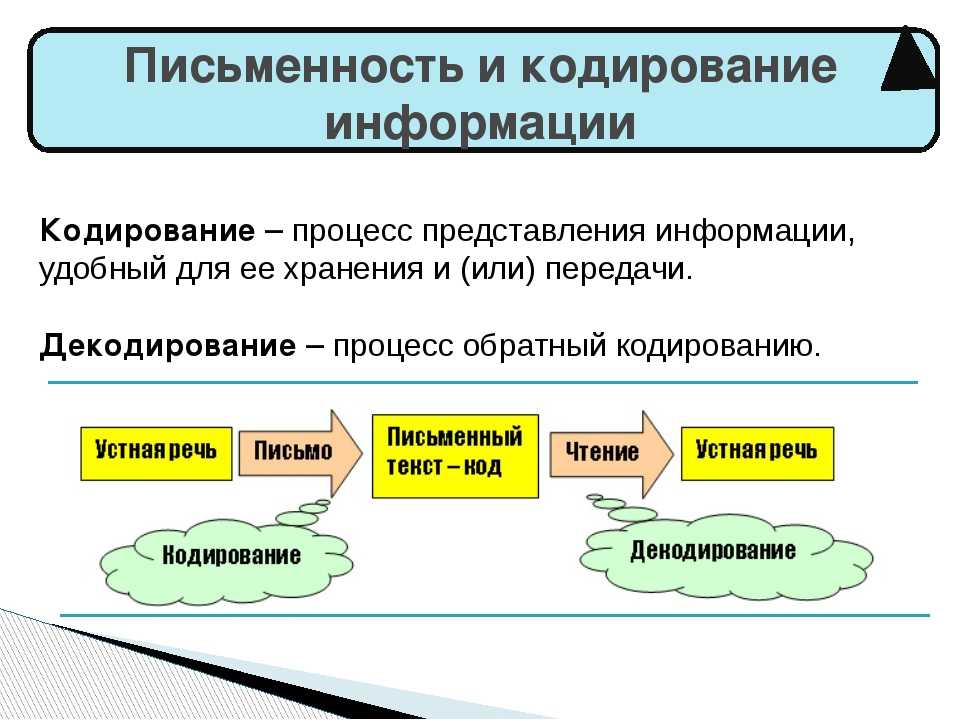
Кодирование и декодирование Кодирование – преобразование входной информации в форму, воспринимаемую компьютером, т.е. двоичный код. Декодирование – преобразование данных из двоичного кода в форму, понятную человеку.

4
Способы кодирования Способы кодирования и декодирования информации в компьютере зависят от вида информации (числа, текст, графические изображения или звук).

5
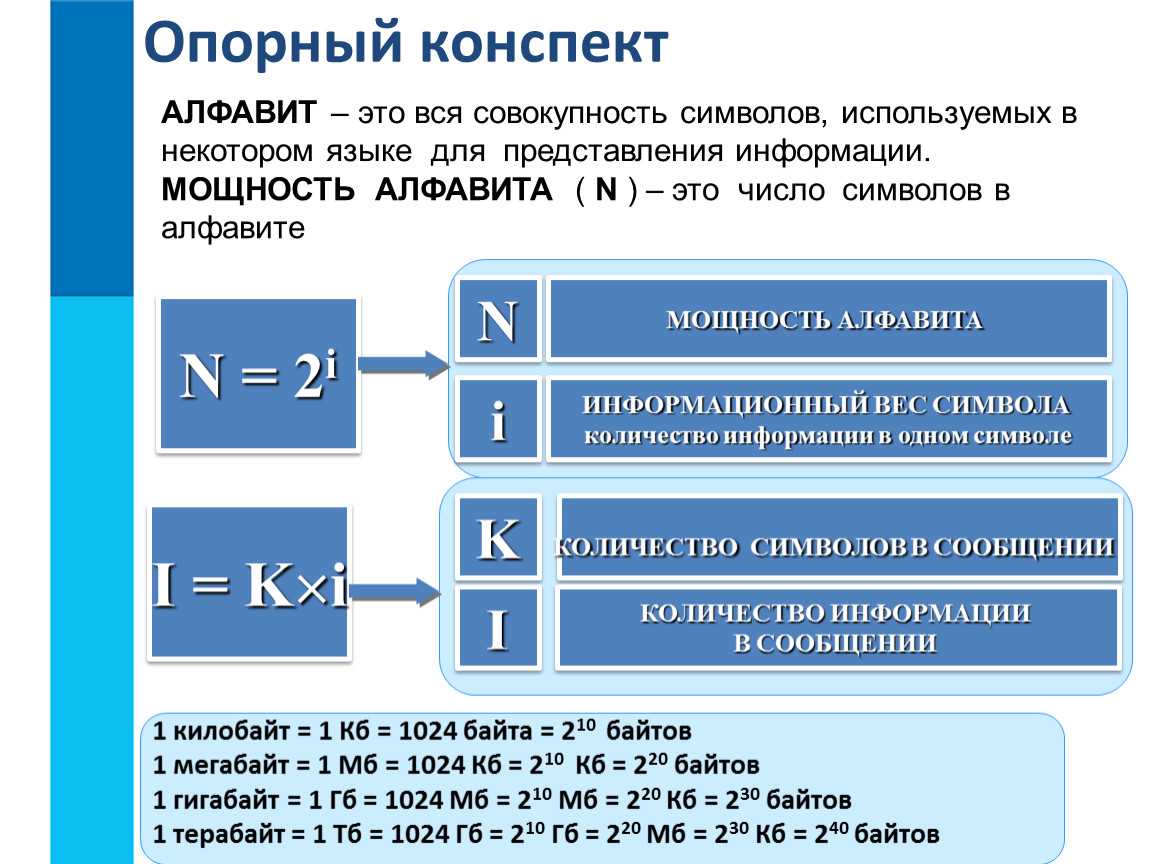
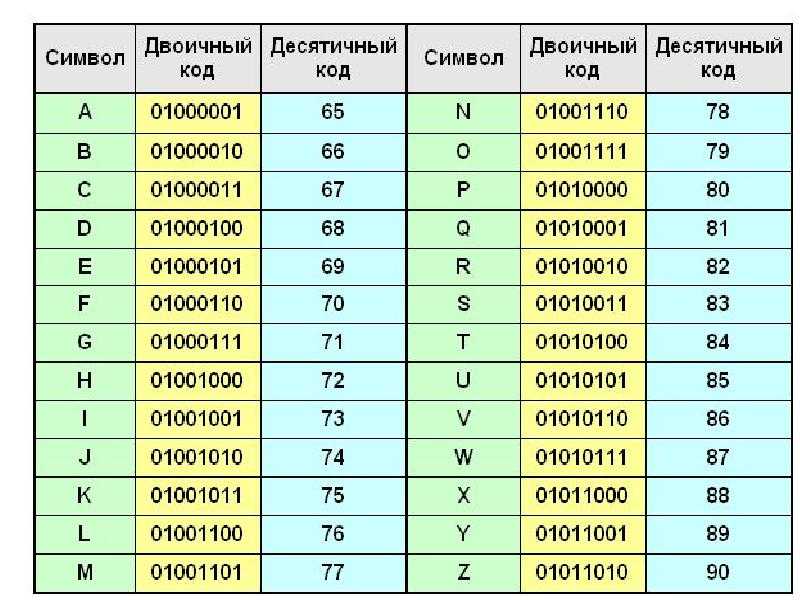
Двоичное кодирование текстовой и числовой информации Для кодирования одного символа (буква, цифра, знак и т.д.) в компьютере используется количество информации = 1 байту (1 байт = 8 битов). Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. 2 8 =256

6
Двоичное кодирование текстовой и числовой информации Кодирование заключается в том, что каждому символу ставиться в соответствие уникальный двоичный код от до (или десятичный код от 0 до 255)
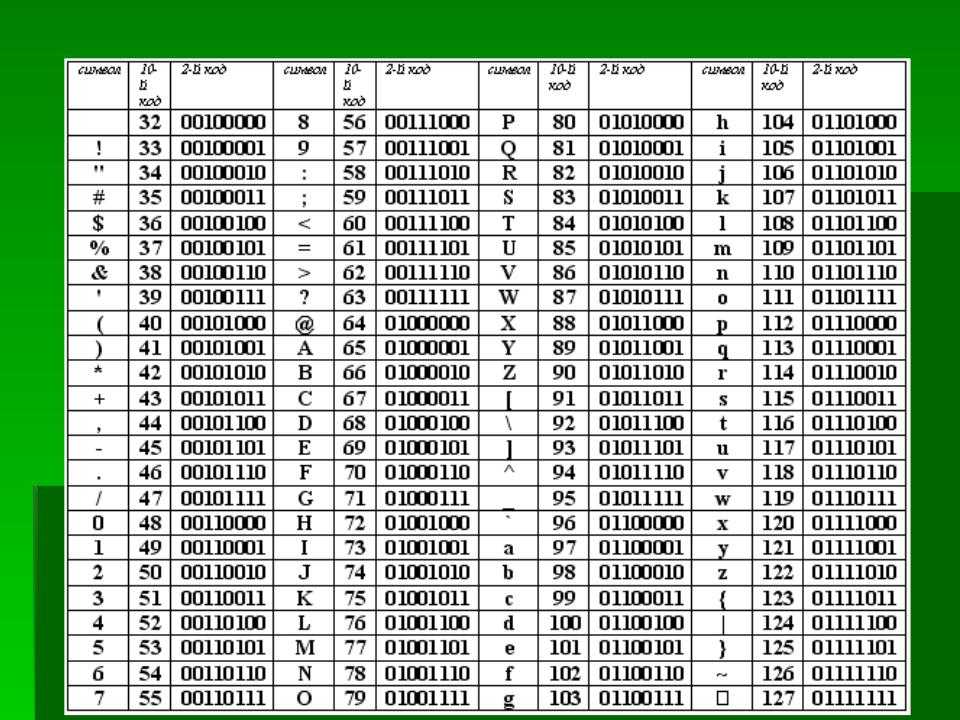
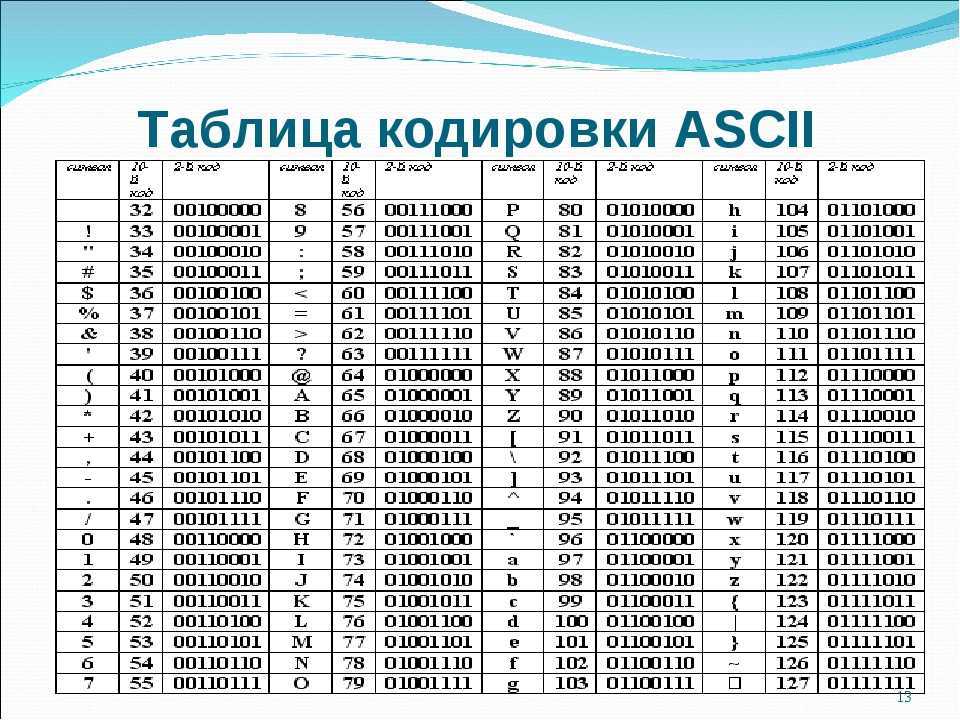
Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей. И таким международным стандартом стала таблица кодировки ASCII
7
Двоичное кодирование текстовой и числовой информации В настоящее время для кодирования текстовой информации в основном используется стандарт Unicode. Единая таблица для всех национальных языков (для 25 существующих письменностей). Для кодировки русских букв используют пять различных кодовых таблиц (КОИ — 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы не будут правильно отображаться в другой кодировке.

8
Таблица стандартной части ASCII
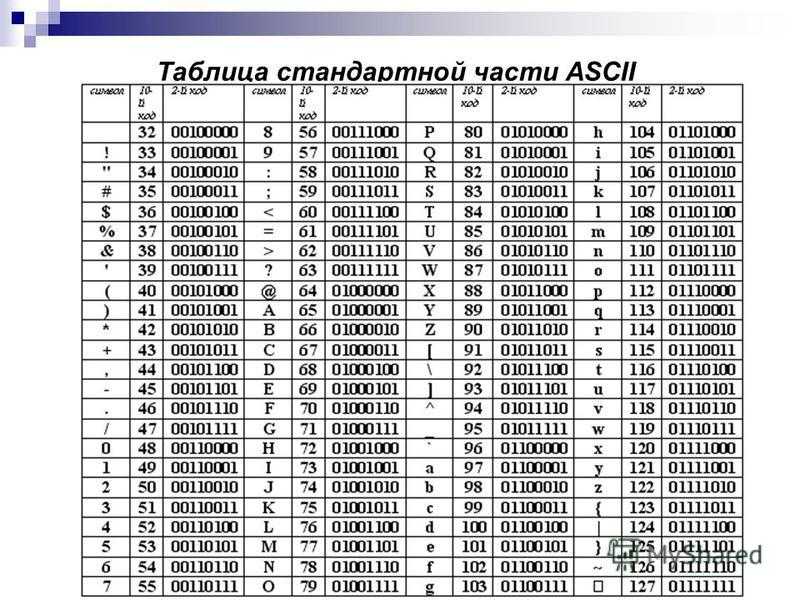
9
Таблица расширенного кода ASCII
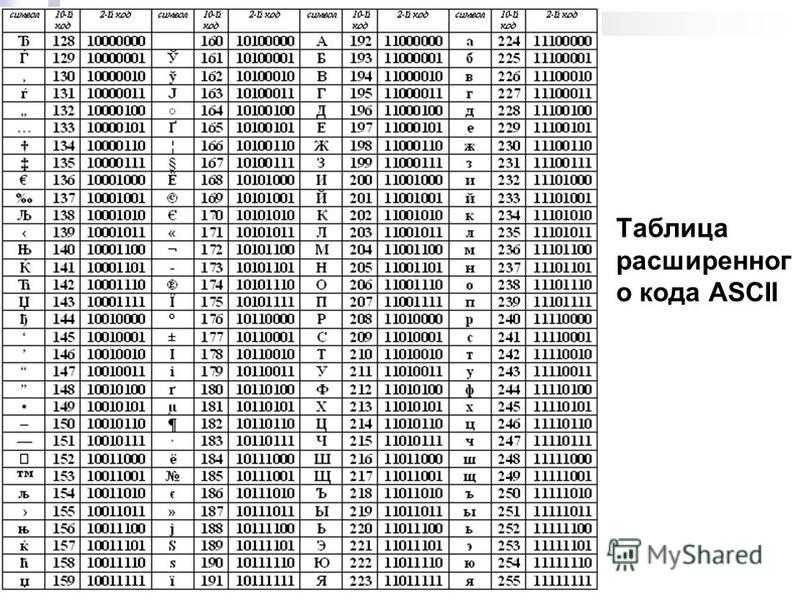
10
Двоичное кодирование графической информации Создавать и хранить графические объекты в компьютере можно двумя способами – как растровое или как векторное изображение. ИЗОБРАЖЕНИЯ РАСТРОВЫЕВЕКТОРНЫЕ Для каждого типа изображений используется свой способ кодирования.
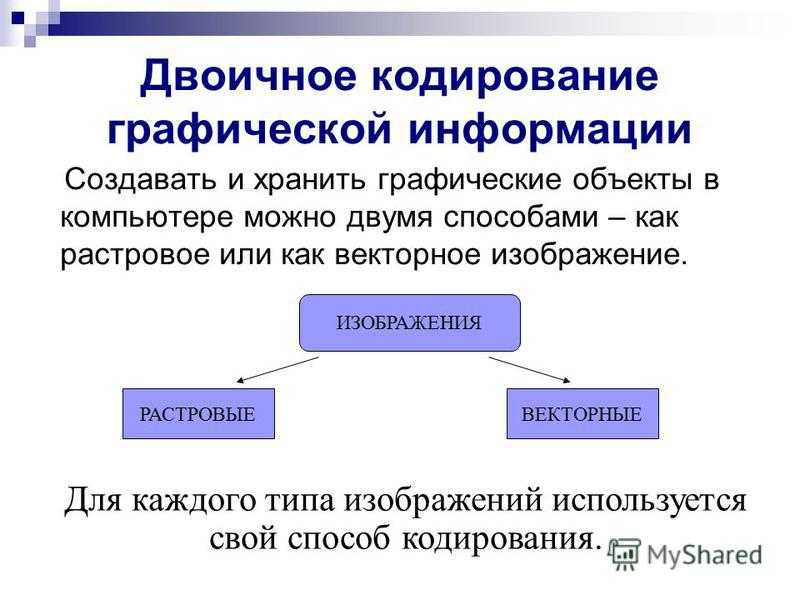
11
Двоичное кодирование растровых изображений Растровое изображение представляет собой совокупность точек (пикселей) разных цветов. Объём растрового изображения определяется как произведение количества точек на информационный объём одной точки.

12
Двоичное кодирование векторных изображений Векторное изображение представляет собой совокупность графических объектов (точка, отрезок, эллипс…). Каждый объект описывается математическими формулами. В памяти компьютера хранится лишь математическая формула и цвет, созданного изображения. Кодирование зависит от программы, в которой создано данное изображение.

13
Цветные изображения Цветные изображения могут иметь различную глубину цвета (количество бит информации, приходящее на 1 точку). N = 2 I N – количество цветов I – количество информации, приходящее на 1 точку

14
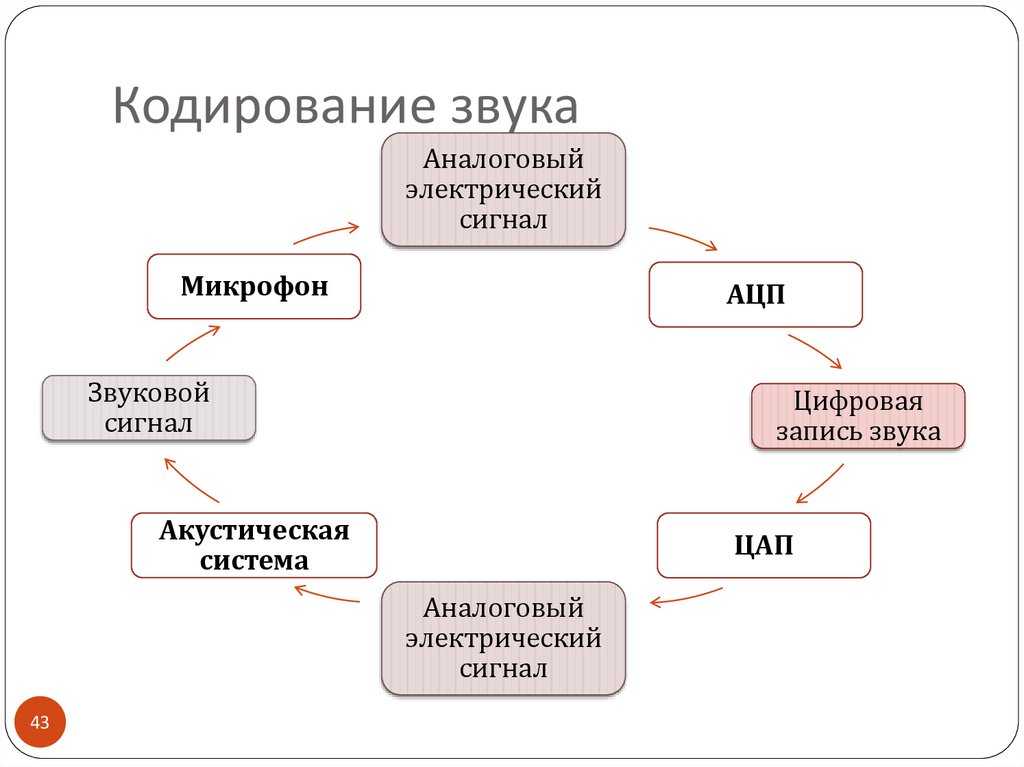
Двоичное кодирование звуковой информации Звук – волна с непрерывно изменяющейся амплитудой и частотой. Чем больше амплитуда, тем он громче для человека, чем больше частота, тем выше тон. В процессе кодирования звукового сигнала производится его временная дискретизация – непрерывная волна разбивается на отдельные маленькие временные участки. Качество двоичного кодирования звука определяется глубиной кодирования и частотой дискретизации.

15
Домашнее задание Выучить записи в тетради. Подготовиться к письменному опросу по 1 и 3 темам.

Стенография
Определение 1
Стенография — это один из способов кодирования текстовой информации с помощью специальных знаков. Она представляет собой быстрый способ записи устной речи. Навыками стенографии могут владеть далеко не все, а лишь немногие специально обученные люди, которых называют стенографистами. Эти люди успевают записывать текст синхронно с речью выступающего человека, что, на наш взгляд, достаточно сложно. Однако для них это не проблема, поскольку в стенограмме целое слово или сочетание букв могут обозначаться одним знаком. Скорость стенографического письма превосходит скорость обычного в $4-7$ раз. Расшифровать (декодировать) стенограмму может только сам стенографист.
Пример 2
На рисунке представлен пример стенографии, в которой написано следущее: «Говорить умеют все люди на свете. Даже у самых примитивных племен есть речь. Язык — это нечто всеобщее и самое человеческое, что есть на свете»:
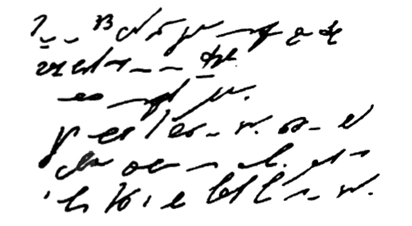 Рисунок 1.
Рисунок 1.
Стенография позволяет не только вести синхронную запись устной речи, но и рационализировать технику письма.
Замечание 1
Приведёнными примерами мы проиллюстрировали важное правило: для кодирования одной и той же информации можно использовать разные способы, при этом их выбор будет зависеть от цели кодирования, условий и имеющихся средств. Если нам нужно записать текст в темпе речи, сделаем это с помощью стенографии; если нужно передать текст за границу, воспользуемся латинским алфавитом; если необходимо представить текст в виде, понятном для грамотного русского человека, запишем его по всем правилам грамматики русского языка
Если нам нужно записать текст в темпе речи, сделаем это с помощью стенографии; если нужно передать текст за границу, воспользуемся латинским алфавитом; если необходимо представить текст в виде, понятном для грамотного русского человека, запишем его по всем правилам грамматики русского языка.
Также немаловажен выбор способа кодирования информации, который, в свою очередь, может быть связан с предполагаемым способом её обработки.
Пример 3
Рассмотрим пример представления чисел количественной информации. Используя буквы русского алфавита, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, запишем: $35$. Допустим нам необходимо произвести вычисления. Естественно, что для выполнения расчётов мы выберем удобную для нас запись числа арабскими цифрами, хотя можно примеры описывать и словами, но это будет довольно громоздко и не практично.







Замечание 2
Заметим, что приведенные выше записи одного и того же числа используют разные языки: первая — естественный русский язык, вторая — формальный язык математики, не имеющий национальной принадлежности. Переход от представления на естественном языке к представлению на формальном языке можно также рассматривать как кодирование.
Двоичная методика
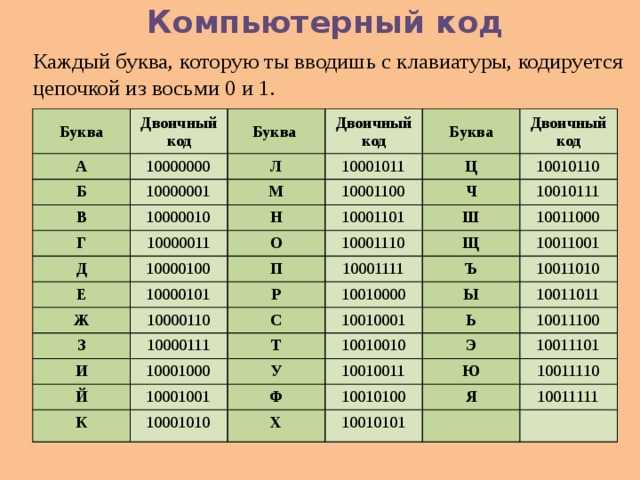
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. В процессе хранения, обработки и передачи информации в компьютере используется особая двоичная система кодирования, алфавит которой состоит всего из двух знаков «0» и «1». Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Связано это с тем, что в цифровой электронике удобнее всего представлять информацию в виде последовательности электрических импульсов: техническое устройство, безошибочно различающее 2 разных состояния сигнала, оказалось проще создать, чем то, которое бы безошибочно различало 5 или 10 различных состояний. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид. Такое кодирование информации принято называть двоичным, на его основе работают все окружающие нас компьютеры, смартфоны и т.п.
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Урок 17§14. Кодирование текстовой информации
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 10 классы | Планирование уроков на учебный год (ФГОС) | Кодирование текстовой информации
![]()
| 14.1. Кодировка ASCII и её расширения | ||
| Кодирование текстовой информации | 14.2. Стандарт Unicode |
14.1. Кодировка ASCII и её расширения
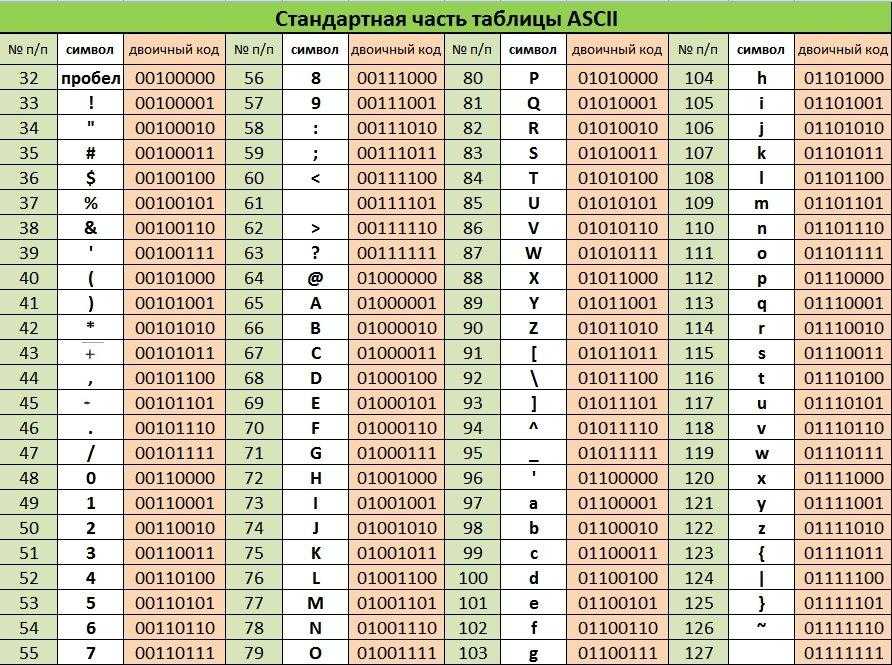
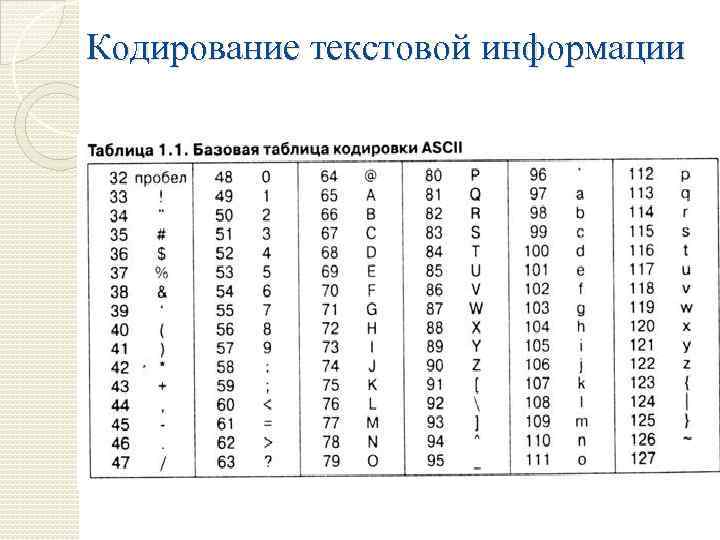
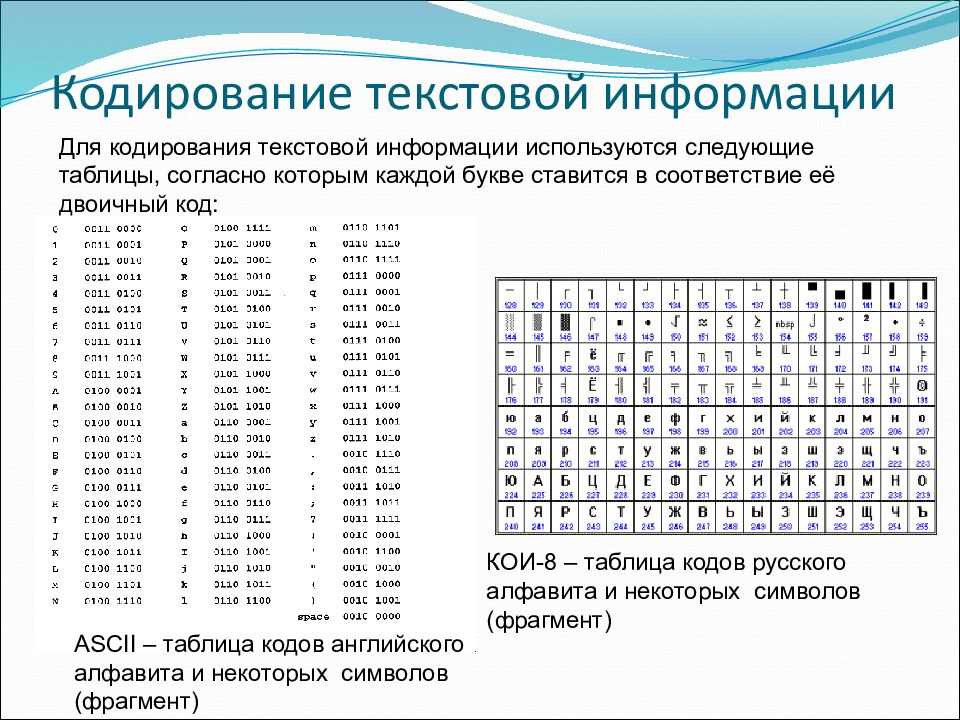
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.).
Этот код 7-битовый: общее количество символов составляет 27 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы.
Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII
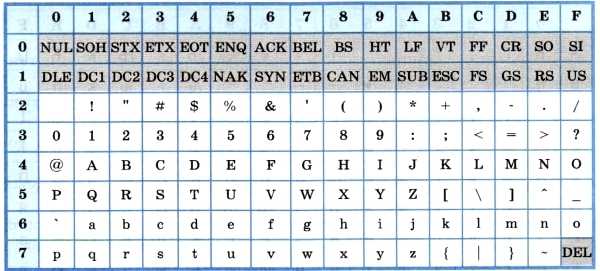
Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Стандарт ASCII рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII -кодировки, в которых применялись однобайтовые коды символов.
При этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п.
Из-за несогласованности этих разработок для многих языков было создано несколько вариантов кодовых таблиц (например, для русского языка их было создано около десятка!).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер.
Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10).
В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы
Обратите внимание на то, что коды русских букв в этих кодировках различны
Таблица 3.9
Кодировка Windows-1251
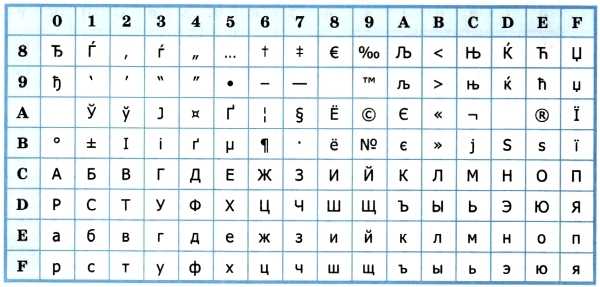
Таблица 3.10
Кодировка КОИ-8

Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах.
Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов.
Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
Cкачать материалы урока
Растровое изображение
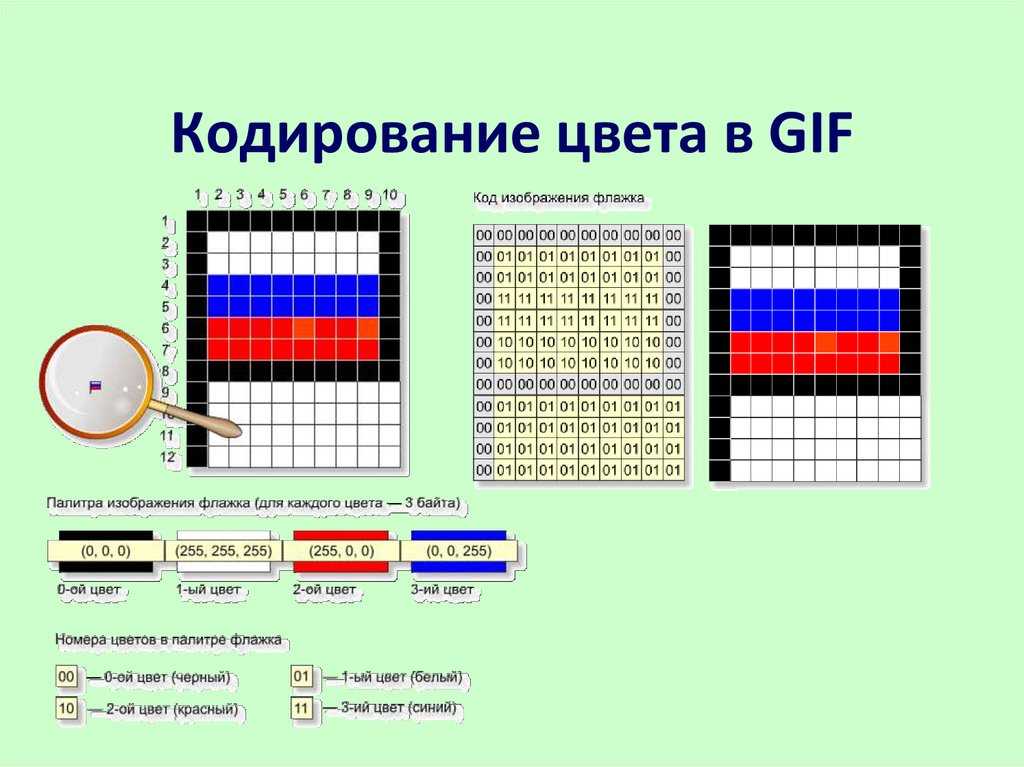
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.



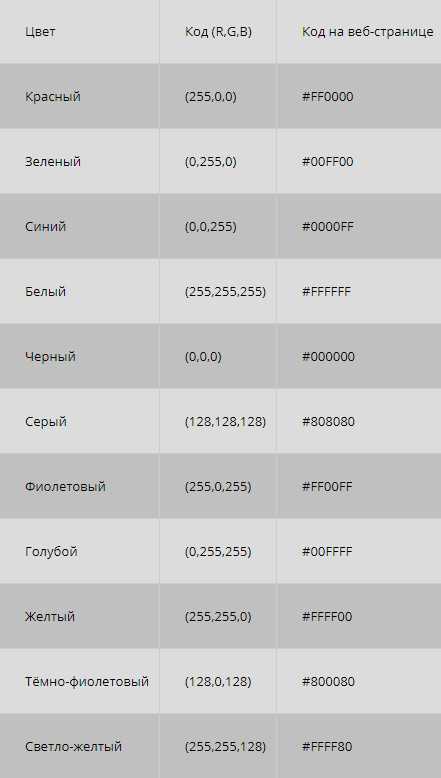
Что делать, если рисунок цветной? Формирование цветного изображения на мониторе осуществляется путём смешивания 3-х основных цветов: синего, красного и зелёного. В этом случае для кодирования цвета пикселя уже не обойтись одним битом. В системе кодирования цветных изображений RGB (R — красный, G — зеленый и B — синий) яркость каждой цветовой составляющей (или, как говорят, каждого канала) кодируется целым числом от 0 до 255. При этом код цвета — это тройка чисел (R,G,B), яркости отдельных каналов. Цвет (0,0,0) — это черный цвет, а (255,255,255) — белый. Если все составляющие имеют равную яркость, получаются оттенки серого цвета, от черного до белого. При кодировании цвета на веб-страницах также используется модель RGB, но яркости каналов записываются в шестнадцатеричной системе счисления (от 0016 до FF16), а перед кодом цвета ставится знак #. Например, код красного цвета записывается как #FF0000, а код синего — как #0000FF.
ИНФОРМАТИКА
Работа 1.4. Представление текстов. Сжатие текстов
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
Задание 1
Определить, какие символы кодировочной таблицы ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в текстовом редакторе «Блокнот», а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.

Задание 2
Закодировать текст с помощью кодировочной таблицы ASCII.
Happy Birthday to you!
Записать двоичное и шестнадцатеричное представления кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
71 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101101 00100000 01010101
01101110 01101001 01110110 01100101 01110010 01110011
01101001 01110100 01111001
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
Задание 6
Во сколько раз увеличится объем памяти, необходимый для хранения текста, если его преобразовать из кодировки KOI8-R в кодировку Unicode?
Задание 7
С помощью табличного процессора Excel построить кодировоч-ную таблицу ASCII, в которой символы будут автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).
Справочная информация
Алгоритм Хаффмана. Сжатием информации в памяти компьютера называют такое ее преобразование, которое ведет к сокращению объема занимаемой памяти при сохранении закодированного содержания. Рассмотрим один из способов сжатия текстовой информации — алгоритм Хаффмана. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьных кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рисунке приведен пример такого дерева, построенного для алфавита английского языка с учетом частоты встречаемости его букв.

Закодируем с помощью данного дерева слово «hello»:
0101 100 01111 01111 1110
При размещении этого кода в памяти побитово он примет вид:
01011000 11110111 11110
Таким образом, текст, занимающий в кодировке ASCII 5 байтов, в кодировке Хаффмана займет только 3 байта.
Задание 8
Используя метод сжатия Хаффмана, закодировать следующие слова:
а) administrator
б) revolution
в) economy
г) department
Задание 9
Используя дерево Хаффмана, декодировать следующие слова:
а)01110011 11001001 10010110 10010111 100000
б)00010110 01010110 10011001 01101101 01000100 000
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти символа входили только управляющие символы и строчные буквы английского алфавита.





С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов.
Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания.
Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение символов: основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Основные кодировки
В начале эры компьютеров на шифровку одного символа отводилось пять бит информации. Причиной этому был сильно ограниченный объём оперативной памяти вычислительных машин тех лет. Зашифровывалось всего 32 элемента, представляющие собой строчные буквы латиницы и символы управления.
Рост производительности так называемого железа привёл к появлению кодировочных таблиц, включающих в себя гораздо большее количество элементов. Так, первой кодировкой, где использовалось уже 7 бит для шифрования одного символа, стала ASCII7. Она включала в себя прописные буквы английского алфавита, цифры в арабском представлении и знаки препинания.

Вскоре появилась расширенная версия ASCII8 — с возможностью использования 256 закодированных двоичным кодом символов, причём вторая половина из 128 ячеек отводилась для национальных алфавитов.
Но для многих языков даже расширенная ASCII8 была недостаточна, поэтому для удовлетворения требований кодировок японского, арабского и других национальных языков, где необходимо большее количество структурных элементов, чем 256, была создана система UNICODE.
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 | 169 | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 < | 155 > | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ~ | тильда |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| левая открывающая квадратная скобка | |
| правая закрывающая квадратная скобка | |
| { | левая открывающая фигурная скобка |
| } | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| двоеточие | |
| ‘ | машинописный апостроф, одинарная кавычка |
| « | двойная кавычка |
| , | запятая |
| . | точка |
| слэш, косая черта, знак дроби | |
| < | левая открытая угловая скобка, знак меньше |
| > | правая закрытая угловая скобка, знак больше |
| \ | обратный слэш, обратная косая черта |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t.
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:
Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR:
#ifdef _UNICODE typedef wchar_t TCHAR;#else typedef char TCHAR;#endif
_T(«строка»)tchar.hПредставление данных и архитектура ЭВМ
Непонятный текст вместо русских букв – исправление
Самая распространенная ситуация при работе с текстовыми данными – это появление «кракозябр» вместо русского языка. Связано это с неправильным кодированием информации.
Чтобы редактировать текстовые документы, рекомендуется использовать Notepad++. Он позволяет программировать на различных языках разработки, а также поддерживает расширяемость через плагины.
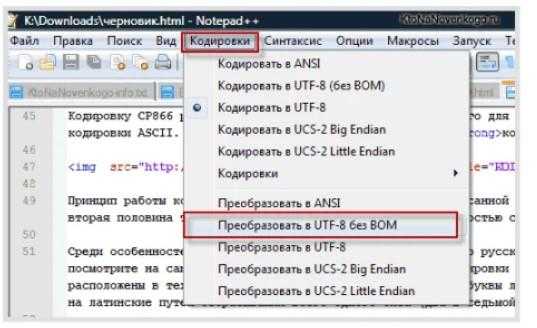
В Notepad++ имеется пункт «Кодирование». Там можно выбрать способ «шифрования» по умолчанию, а также воспользоваться преобразованием. Рекомендуется останавливаться на таблице UTF-8 без BOM. В этом случае в начало документа не вставляются три дополнительных байта.
Windows 1251
Windows 1251 – это «продукт», созданный компанией Microsoft. Его появление обусловлено популярностью развития графических операционных систем. Псевдографика для них стала ненужным элементом. Все это привело к появлению полноценной группы, которая по-прежнему считалась расширенной интерпретацией ASCII (где один символ теста будет закодирован всего одним байтом данных), но уже без символьной псевдографики.
Соответствующая группа относилась к так называемым ANSI-кодировкам. Они разрабатывались американским институтом стандартизации. Говоря простым языком, это кириллица для варианта с поддержкой русского алфавита. Наглядный пример – Windows 1251.
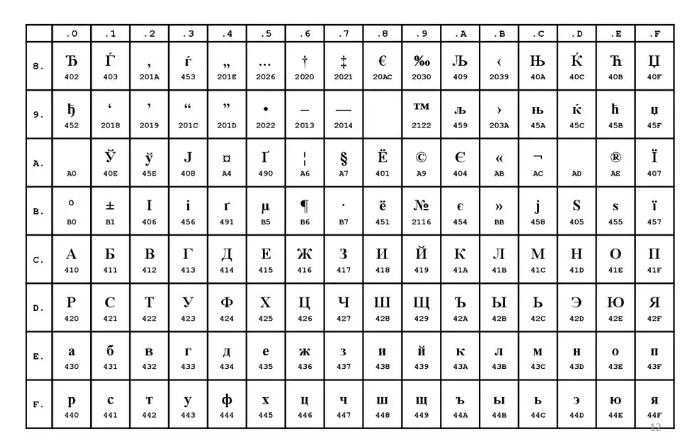
В нем нет псевдографики. Их место было отведено под недостающие:
- знаки русской типографии (за исключением ударения);
- славянские языки (украинский, белорусский и так далее).
В Windows 1251 нет совместимости с CP866. Если попытаться отобразить их между собой, на экране появится неточный текст сообщения, а бессмысленный знаковый набор (простыми словами – «кракозябры»).
Windows 1251 используется в семействе Windows. В основном встречается в операционных системах начала 90-х годов. Кириллица здесь отображается в алфавитном порядке.